
面向机器学习型区域滑坡易发性评价的训练样本采样方法
|
洪浩源(1985-), 男, 江苏南京人, 博士, 讲师, 研究方向为人工智能和自然灾害易发性空间预测研究。E-mail: haoyuan.hong@nuist.edu.cn |
收稿日期: 2023-12-28
修回日期: 2024-06-27
网络出版日期: 2024-07-30
基金资助
国家自然科学基金项目(41871300)
A new training data sampling method for machine learning-based landslide susceptibility mapping
Received date: 2023-12-28
Revised date: 2024-06-27
Online published: 2024-07-30
Supported by
National Natural Science Foundation of China(41871300)
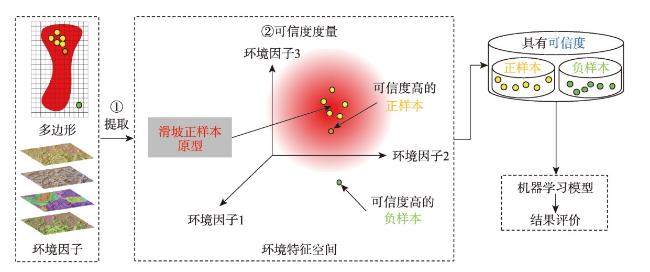
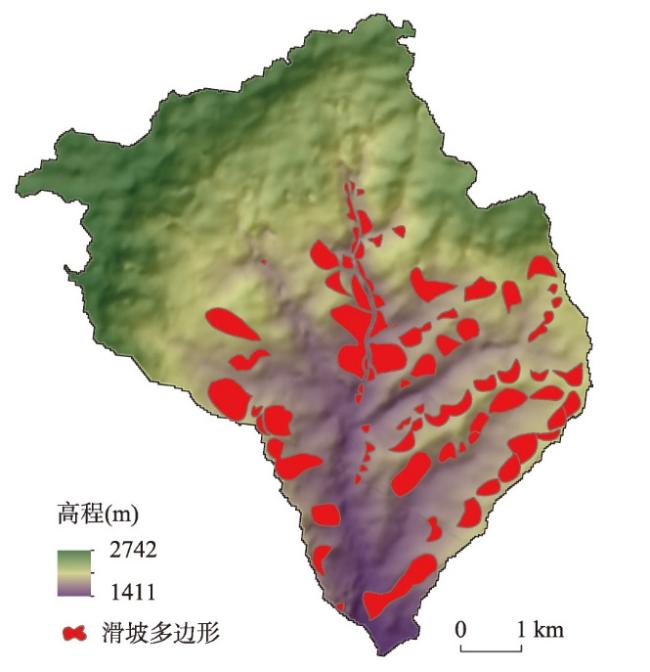
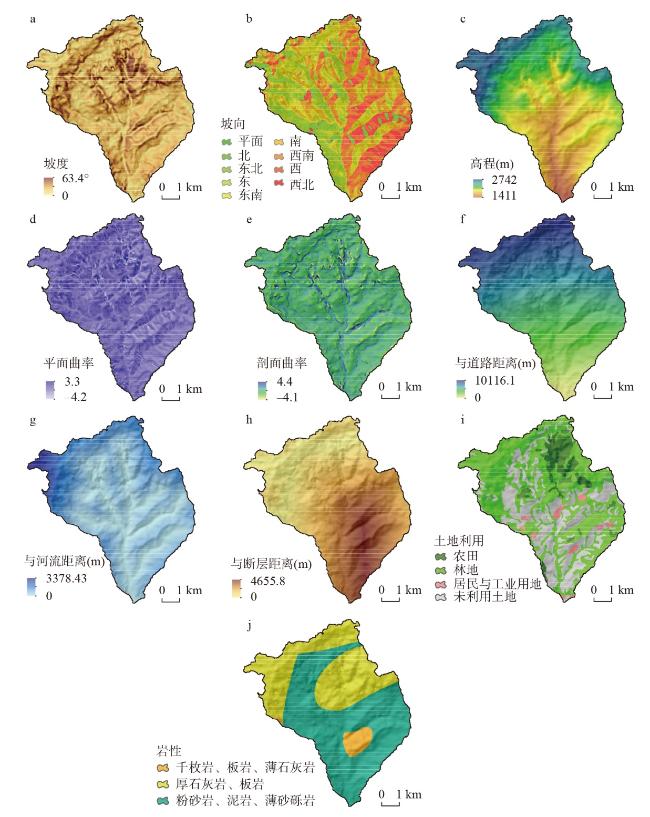
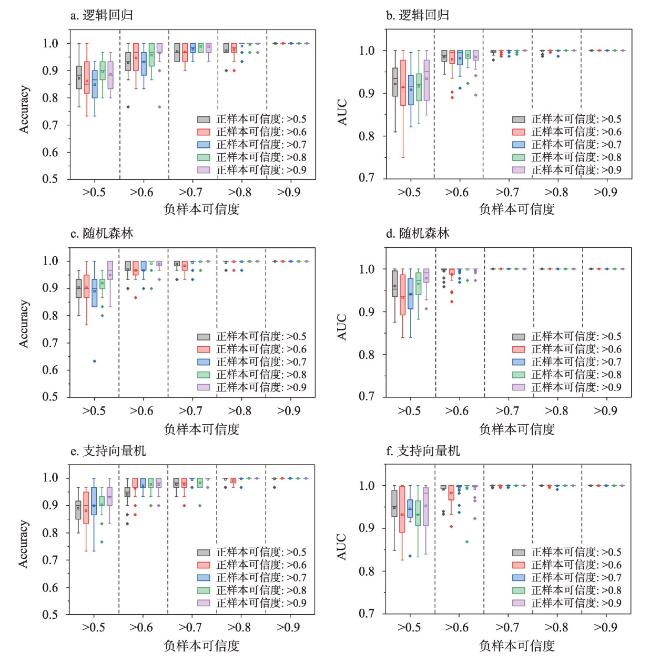
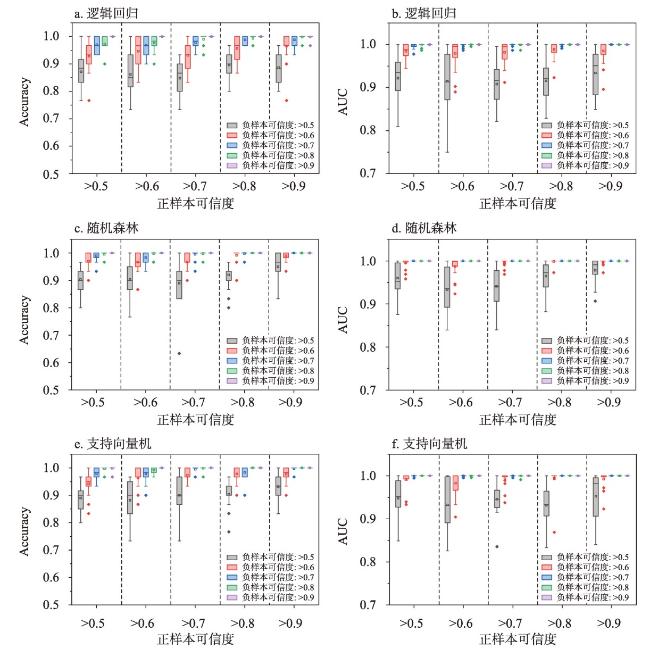
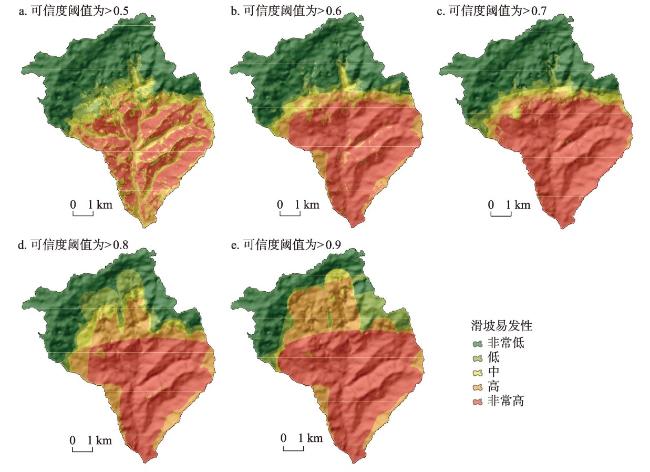
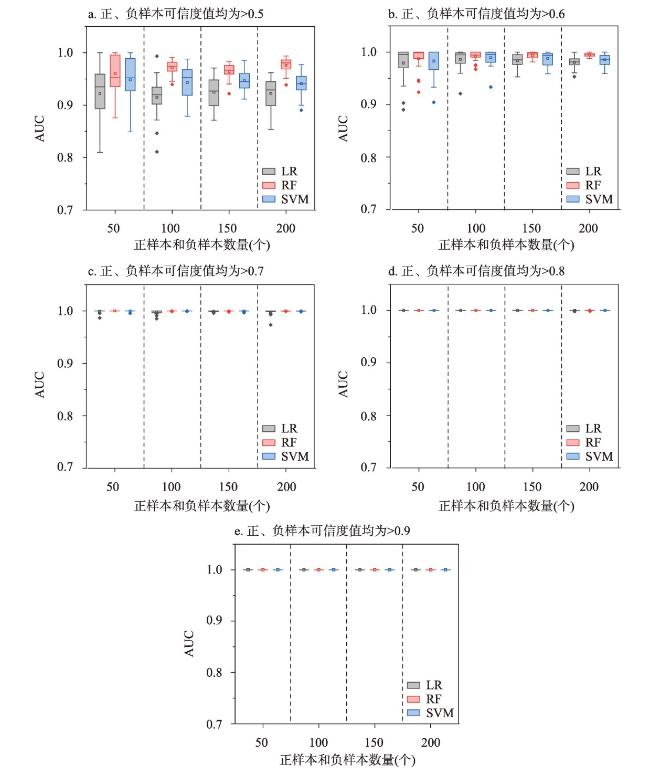
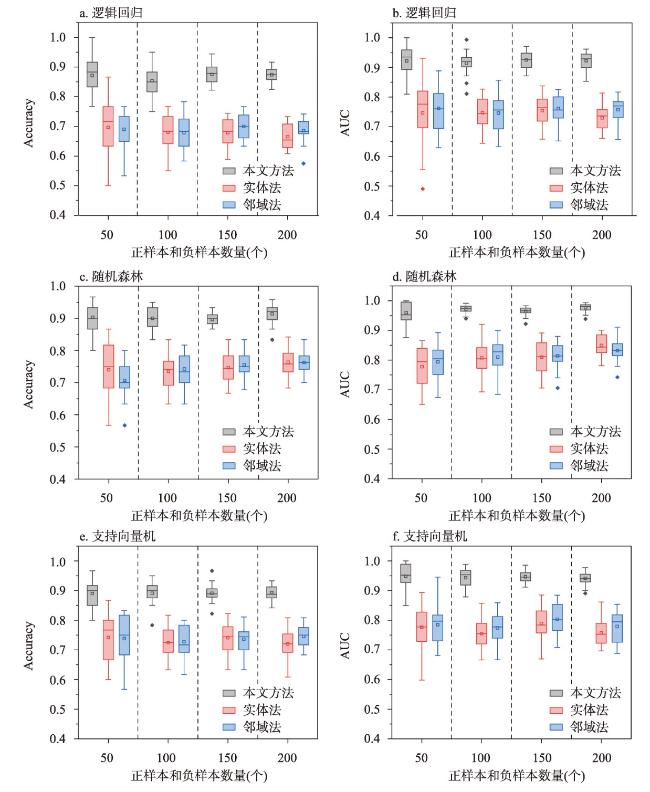
训练样本在基于机器学习的区域滑坡易发性评价中具有重要作用,训练样本通常是由滑坡(正样本)和非滑坡(负样本)组成,由采样方法采集得到。然而,现有正样本采样方法均没有度量所采集正样本的可信度,使得所采集训练样本可靠性得不到保证,制约了机器学习的区域滑坡易发性评价效果。针对这一问题,本文提出滑坡正样本原型采样方法(PBS),该方法利用某点与滑坡正样本原型的地理环境相似度和不相似度分别度量正样本与负样本的可信度,基于互斥法设置可信度阈值采集训练样本。以甘肃省油房沟流域为研究区,将PBS与已有代表性采样方法分别对油房沟流域构建基于逻辑回归、支持向量机和随机森林的滑坡易发性推测模型,对比有可信度和无可信度样本下的滑坡易发性评价效果。结果发现,正样本和负样本可信度与滑坡易发性评价效果分别呈现“波动上升”与“正相关”的特点,PBS方法在基于3种机器学习模型的滑坡易发性评价的验证精度(Accuracy)和接收者操作特征曲线下面积(AUC)值比已有代表性采样方法分别至少提高了14.7%和14%,且标准差均较小,表明本文所提出方法是有效的。

洪浩源 , 王德生 , 朱阿兴 . 面向机器学习型区域滑坡易发性评价的训练样本采样方法[J]. 地理学报, 2024 , 79(7) : 1718 -1736 . DOI: 10.11821/dlxb202407006
Training samples play an important role in machine learning-based regional landslide susceptibility evaluation. These samples consist of both landslide (positive) and nonlandslide (negative) samples collected through various sampling methods. However, existing methods for positive sample collection do not measure the reliability of the collected samples, leading to uncertainty in terms of reliability. To address this issue, this paper presents a landslide prototype sampling method (PBS). This method uses the geographical similarity and dissimilarity between a certain point and the landslide positive sample prototype to measure the reliability of positive and negative samples, respectively. A reliability threshold is set based on a mutual exclusion method to collect training samples. The Youfanggou Basin in Gansu province was chosen as the research area. The PBS and existing representative sampling methods were used to construct landslide susceptibility prediction models based on logistic regression, support vector machines, and random forests for the Youfanggou Basin. The evaluation effects of landslide susceptibility were compared between the reliable and nonreliable samples. The reliability of the positive and negative samples exhibited a "fluctuating increase" and "positive correlation", respectively, in the evaluation of landslide susceptibility. The PBS method improved the accuracy and area under the receiver operating characteristic curve (AUC) of the landslide susceptibility evaluation based on the three machine learning models by at least 14.7% and 14%, respectively, compared to the existing representative sampling methods, and the standard deviation was small, which indicates that the method proposed in this article is effective.
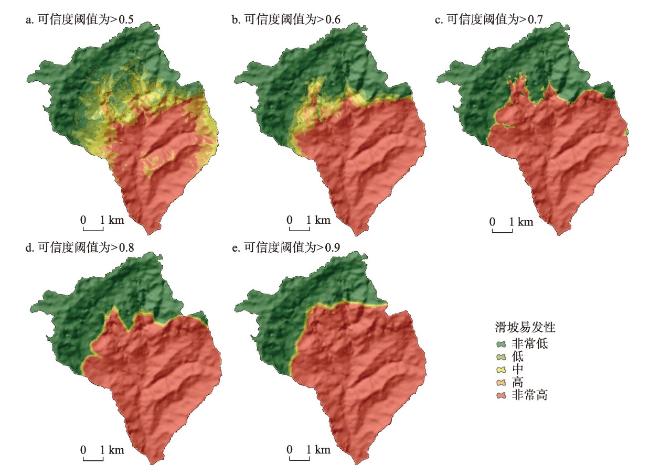
图7 基于逻辑回归模型和可信度采样法的滑坡易发性空间分布Fig. 7 Landslide susceptibility map using the LR model based on reliability-based sampling |
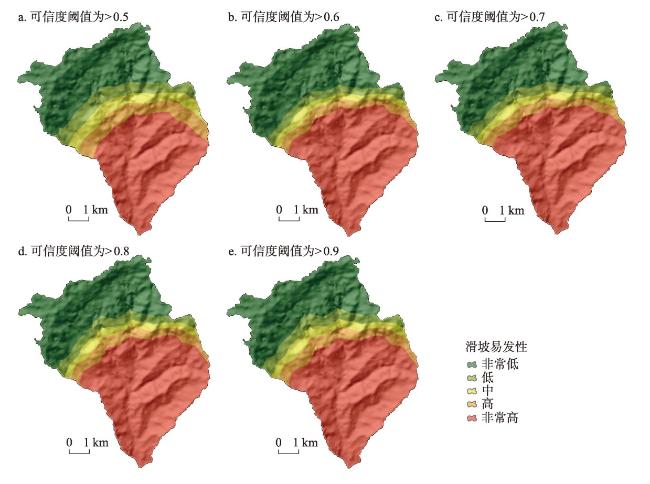
图8 基于随机森林模型和可信度采样法的滑坡易发性空间分布Fig. 8 Landslide susceptibility map using the RF model based on reliability-based sampling |
| [1] |
|
| [2] |
[申泽西, 张强, 吴文欢, 等. 青藏高原及横断山区地质灾害易发区空间格局及驱动因子. 地理学报, 2022, 77(5): 1211-1224.]
|
| [3] |
|
| [4] |
[张玺国, 周雄冬, 徐梦珍, 等. 西藏地质灾害易发性及对水能开发适宜度影响. 地理学报, 2022, 77(7): 1603-1614.]
|
| [5] |
|
| [6] |
[胡胜, 邱海军, 王宁练, 等. 地形对黄土高原滑坡的影响. 地理学报, 2021, 76(11): 2697-2709.]
|
| [7] |
[武雪玲, 杨经宇, 牛瑞卿. 一种结合SMOTE和卷积神经网络的滑坡易发性评价方法. 武汉大学学报(信息科学版), 2020, 45(8): 1223-1232.]
|
| [8] |
|
| [9] |
[杜悦悦, 彭建, 赵士权, 等. 西南山地滑坡灾害生态风险评价: 以大理白族自治州为例. 地理学报, 2016, 71(9): 1544-1561.]
|
| [10] |
[曾营, 张迎宾, 张钟远, 等. 基于X-多层感知器耦合模型的滑坡易发性评价: 以贵州省松桃自治县为例. 山地学报, 2023, 41(2): 280-294.]
|
| [11] |
|
| [12] |
[陈涛, 钟子颖, 牛瑞卿, 等. 利用深度信念网络进行滑坡易发性评价. 武汉大学学报(信息科学版), 2020, 45(11): 1809-1817.]
|
| [13] |
[鲍帅, 刘纪平, 王亮. 联合DBSCAN聚类采样和SVM分类的滑坡易发性评价. 震灾防御技术, 2021, 16(4): 625-636.]
|
| [14] |
[黄发明, 殷坤龙, 蒋水华, 等. 基于聚类分析和支持向量机的滑坡易发性评价. 岩石力学与工程学报, 2018, 37(1): 156-167.]
|
| [15] |
[周超, 甘露露, 王悦, 等. 综合非滑坡样本选取指数与异质集成机器学习的区域滑坡易发性建模. 地球信息科学学报, 2023, 25(8): 1570-1585.]
|
| [16] |
|
| [17] |
|
| [18] |
[唐川, 朱静. 澜沧江中下游滑坡泥石流分布规律与危险区划. 地理学报, 1999, 54(Suppl.1): 84-92.]
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
[周晓亭, 黄发明, 吴伟成, 等. 基于耦合信息量法选择负样本的区域滑坡易发性预测. 工程科学与技术, 2022, 54(3): 25-35.]
|
| [23] |
|
| [24] |
[方苗, 张金龙, 徐瑱. 基于GIS和Logistic回归模型的兰州市滑坡灾害敏感性区划研究. 遥感技术与应用, 2011, 26(6): 845-854.]
|
| [25] |
|
| [26] |
[缪亚敏, 朱阿兴, 杨琳, 等. 一种基于地理环境相似度的滑坡负样本可信度度量方法. 地理科学进展, 2016, 35(7): 860-869.]
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
[缪亚敏. 滑坡敏感性评价中的负样本采样方法研究[D]. 南京: 南京师范大学, 2016.]
|
| [32] |
|
| [33] |
[缪亚敏, 朱阿兴, 杨琳, 等. 滑坡敏感性制图中一种新型的负样本采样方法. 地理与地理信息科学, 2016, 32(4): 61-67.]
|
| [34] |
[缪亚敏, 朱阿兴, 杨琳, 等. 滑坡敏感性评价对BCS负样本采样的敏感性. 山地学报, 2016, 34(4): 432-441.]
|
| [35] |
[缪亚敏, 朱阿兴, 杨琳. 滑坡危险度制图精度评价指标的有效性研究. 自然灾害学报, 2017, 26(2): 115-122.]
|
| [36] |
[谌文武, 赵志福, 刘高, 等. 兰州—海口高速公路甘肃段工程地质问题研究. 兰州: 兰州大学出版社, 2006: 19-22.]
|
| [37] |
[陈耀乾. 甘肃省武都县地质灾害调查与区划报告. 甘肃省地质环境监测总站, 2001.]
|
| [38] |
[董抗甲. 甘肃省舟曲县地质灾害调查与区划报告. 甘肃省地质环境监测总站, 2003.]
|
| [39] |
|
| [40] |
|
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}