聂可 , 王振声, 罗平
, 王振声, 罗平
NIE Ke, WANG Zhensheng, LUO Ping
通讯作者:
版权声明: 2017 地理科学进展 《地理科学进展》杂志 版权所有
基金资助:
作者简介:
作者简介:聂可(1988-),女,湖北黄冈人,博士,助理研究员,主要从事城市定量分析与表达研究,E-mail: nieke@whu.edu.cn。
展开
摘要
随着信息通信技术高速发展,地理相关大数据使得传统的空间分析面临着机遇与挑战。平面空间分析方法在分析网络空间点要素空间过程、揭示其空间分布时的弊端日益凸显,由此对探索网络约束点要素特定的分析方法的关注度不断提高。本文定义了网络约束的思想,详细阐述了网络约束点格局分析方法体系,并分别从网络约束点格局的理论和应用出发,梳理了网络约束点格局分析的一阶方法、二阶方法及其他方法上的研究进展,总结了网络约束点格局分析在交通安全领域、犯罪学领域和其他城市点要素中的典型应用,最后在方法与应用层面,讨论近年重要的研究动向及未来的发展趋势。
关键词:
Abstract
With the rapid development of information and communication technology, the explosive amount of spatial big data creates both opportunities and challenges in the field of spatial analysis. Shortcomings of the traditional analytic paradigm for spatial process and spatial pattern analyses of network-constrained spatial point event have been revealed. Therefore, many studies have attempted to develop novel approaches for network-constrained point event analysis. In this article, we first conceptually defined network-constrained phenomenon and presented in detail the methodological framework of network-constrained point pattern analysis. Then we generalized the development status of methods of network-constrained point pattern analysis, including first-order effect method, second-order effect method, among others, and summarized the present situation of typical applications in the research of traffic safety, criminology, and other point events in urban context. In the end, current trends and future directions are discussed with regard to research methods and applications.
Keywords:
大数据的蓬勃发展,地理相关大数据的产生为地理空间分析的发展提供了巨大的数据基础,也带来机遇和挑战(王劲峰等, 2014)。空间分析是分析地理相关数据的一系列技术,空间格局分析作为空间分析中最重要的内容,用于描述空间个体某一时刻在空间的散布状态,是地理学及其交叉学科中广泛关注的主题。空间格局分析的方法很多,包括样方法、点格局分析法、分形理论等,其中,点格局分析方法将每个个体抽象为二维空间中的点,可分析任意尺度的空间分布格局,是最常用的空间格局分析方法。平面点格局分析的理论与方法是以“理想空间”假设为前提,即用欧氏距离度量的无边界齐次空间。然而,现实世界中,“理想空间”通常并不存在,多种事件或实体的发生受到网络约束,如道路网络上的机动车碰撞、河流中的水生物、沿街的商店等。同时,网络可以是有形的网络也可以是无形的网络,与其对应的对象或实体也呈现多种形态。研究表明,“理想空间”中的“绝对空间”(Gatrell, 1983)的观点不适合欧氏空间中自身的子空间问题,特别是对于网络约束事件或实体的格局分析,需要充分考虑到网络的特性,采用网络约束空间点格局分析的方法进行探讨(Yamada et al, 2010)。
近年来,网络约束(network-constrained)现象受到了学者们的关注。Yamada等(2007)以街道网络为例,正式定义了街道网络约束要素,即对于任何现象,如果其位置由街道地址表示,且其位置严格限定在该街道网络上,称其为街道网络约束要素,并根据该要素与街道网络的位置关系,分为街道网络上的要素和街道网络旁的要素。本文认为,空间中任何要素,如果其自身的位置的改变受到网络的约束,那么则称该要素为网络约束要素,即广义的网络约束要素;对网络约束要素进行的分析则称为网络约束分析,对网络约束要素进行的格局分析称为网络格局分析。对于网络约束要素,点要素是最常见最直观的一类要素,对于网络约束点要素的格局分析称为网络约束点格局分析。本文主要阐述网络约束点格局分析的思想,并从网络约束点格局分析的理论和应用层面出发,梳理并概述其研究进展。
地学分析中,常用的两种概念模型为:①对象模型,即认为客观世界由离散的实体构成;②场模型,即认为客观世界是连续的场(Burrough et al, 1998)。网络约束建模是以传统空间分析理论框架为基础,网络地理世界由网络实体(network-like entities)和网络约束实体(network-constrained entities)构成,分别将传统的对象模型和场模型拓展到网络约束空间,对网络和网络要素分别进行建模,形成网络对象模型、网络要素对象模型、网络场模型、网络要素场模型。
2.1.1 网络建模
网络是一种连通关系的概念模式,具有线状特征,由节点和连线构成。地理网络是地理空间中一种特殊的线状要素,由弧段(segments)、结点(nodes)、拐点(inflection nodes)、站(stops)、中心(centers)、障碍(barriers)等空间元素构成,有着不同的存在形式,如:具体网络和抽象网络、自然网络和人工网络等。在网络对象建模中,采用几何网络进行描述。假设地理网络对象由二维或三维空间的有限数量和有限长度的弧段构成,每个弧段由端点相连且两点间至少有一条网络弧段,定义端点集合为
地理网络可用矢量数据模型和栅格数据模型进行存储,其中矢量数据模型最为常用,但是对于网络空间连续性变化属性的描述,采用栅格数据模式更为合理。网络栅格模型来源于平面栅格模型的扩展,将传统的像素的思想拓展到网络空间的格点,即使用相等的长度在弧段上取点。
2.1.2 网络约束点建模
根据要素与网络的拓扑关系,可分为网络上的要素和网络沿线要素,要素可以是点要素、线要素、面要素,如图2所示。网络上的要素类型主要有点要素和线要素,点要素以点的形式存在于网络空间,如交通事故、交通信号灯、车辆等;网络上的线要素,以线的形式存在于网络空间,如道路沿线的地下管线等。网络沿线要素,其要素的抽象建模较为复杂,如沿街的建筑物,可依据建筑物质心、建筑物入口等将其抽象为沿街的空间点,也可依据建筑物边线、建筑物中心线将其抽象成平行于沿街的空间线。此外,还存在网络空间与线状要素、面状要素的交叉现象。同样,可通过在点状、线状、面状目标附近建立估算值的场函数来表示网络约束要素,以场函数的方法对网络要素进行建模。
网络约束空间点要素同平面空间点要素一样,其发生可能是必然也可能是偶然的。网络约束空间点要素的空间格局是其空间过程的一种实现,随机零假设是网络空间分析的基础,可分别建立网络对象随机空间模型和网络场随机空间模型。本文主要讨论的网络对象随机模型主要是针对网络空间点要素对象,点要素的空间随机过程包括属性要素的随机、空间要素的随机,亦即是点要素的属性随机而空间位置固定、点要素的属性固定而空间位置随机(即随机空间过程)、点要素的属性随机且空间位置随机(即归一化空间过程)。那么网络约束空间点过程可以作如下定义:
令
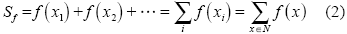
式中:
如果函数
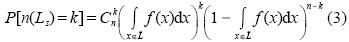
如果过程强度函数
网络约束点格局是特定网络空间点过程的结果,空间数据、空间模式、要素地图均是点过程可能的一种实现。空间点格局分析关注观测点要素在地图上分布,一方面揭示空间点要素分布的表征形式,即随机、规则、聚集;另一方面,描述同类或不同种类点要素空间相关性,可分为基于一阶特性的方法(first-order effect)和基于二阶特性的方法(second-order effect)。其中,一阶特性是针对点对象的潜在特性,度量其空间过程的均值的全局变化,如样条分析法、核密度估计法等;二阶特性主要针对点要素的空间模式,度量空间过程的局部偏差进而探测其空间交互结构,如最邻近统计、高/低聚类、多距离空间聚类分析、F函数等(Bailey et al, 1995;O'Sullivan et al, 2003)。如果点要素的空间过程统计量(如均值、方差、协方差等)不依赖空间绝对位置,那么则认为该空间过程是平稳的(homogeneous point process);如果点要素的空间过程统计量随着空间位置变化而变化,那么则认为该空间过程是非平稳的(heterogeneous point process)。空间过程的一阶特性和二阶特性可形成类似的空间分布模式,但清楚判别二者之间的差别较困难,目前在常用的空间统计方法中往往只是探讨一种特性而暂时不考虑另一种特性(Yamada et al, 2004)。
网络空间点格局分析的基本思路为:进行空间描述性测度,包括一阶效应测算或二阶效应测算;建立完全随机假设;进行空间统计推断,判断观测模式的异常程度,其分析框架如下(图3):
2.3.1 网络约束空间点格局的趋势描述
网络约束空间点格局的趋势描述对平面点格局分析方法的扩展,即是采用基于密度的方法和基于距离的方法对网络空间点的分布情况进行探测。网络密度法主要是对网络空间点格局的一阶效应进行测度,通过对观测值的空间分布密度的量化来实现,即将整个研究区域按照网络距离的方式划分为若干单元,在每个单元周围建立网络邻域来计算其密度,其中比较有代表性为网络核密度估计法为;基于距离的方法主要是对网络约束点格局的二阶效应进行测度,是通过对点之间的距离进行测度来实现,具有代表性的是网络最邻近距离法。
2.3.2 网络约束空间点格局的空间统计推断
网络约束空间点格局的描述可以在某种程度上揭示空间点模式的分布特点,但由于缺乏严格的统计推断,无法对空间分布的聚集程度的进行定量评估(O'Sullivan et al, 2013)。在网络空间点格局分析过程中,通常采用假设检验的方法,根据观测模式的测度,来推断产生该观测模式的概率,即推断观测模式的空间过程。统计检验的一般过程为:首先对观测模式提出零假设,然后选择假设检验的显著性水平,分别求出并比较临界值和检验统计量的实际值,从而判断拒绝或接受零假设。地理分析中的可用数据常是研究区域内的枚举普查数据,零假设主要是通过随机化零假设和归一化零假设来实现。随机化零假设认为,假设观测的空间模式是空间过程的结果之一,观测值固定而观测值的空间排列不固定;归一化零假设认为假设观测模式是从更大的总体中通过随机抽样获得的,观测值和观测值的排列均不固定,并要求数据值正态分布。在网络空间点格局统计推断中,常常使用空间随机零假设,根据空间点过程的特点选择不同的随机过程模型,包括:完全空间随机过程模型(CSR)、 Cox过程、 Markov point processes过程模型。通常情况下,对观测模式提出完全随机模式零假设,即假设空间点过程为同质泊松过程,每个要素在研究区域的任何位置上出现的概率相等,且相互独立,通过计算并比较观测值和期望值,进行显著性检验,从而判断空间过程是随机分布、聚类分布或均匀分布。其中,CSR 假设的显著性检验方法包括 Monte Carlo 检验、K-S 检验 (王远飞等, 2007)。
网络约束现象作为一种独特的地理形态,网络约束点格局分析是以平面格局分析为基础,其随点格局分析理论的发展而发展。网络约束点格局分析方法主要是针对网络约束点要素的一阶特性和二阶特性展开研究。以下分别对点格局分析、网络约束点格局分析理论发展与网络约束点格局分析方法三个层面的研究情况进行阐述。
20世纪50年代末到60年代初,随着地理学古典范式的衰落,空间分析范式的兴起,空间点格局分析被首次提出,其借用植物生态学领域的空间格局描述,针对人口分布(King, 1962)、城市零售店的空间位置分析(Rogers, 1965)、冰河时期的冰丘分布(Trenhaile, 1971)等进行应用分析,继而逐渐应用于生物统计(Bartlett, 1975)、地统计(Cressie, 1993)、空间统计(Diggle, 1983)等其他领域。点对象空间格局分析的理论思想首次由Ripley在皇家统计会提出(Ripley, 1977),随后Diggle等对其进行完善,从而能够直观地表达不同尺度下的空间点格局(Diggle, 1983)。然而,由于零假设与现实的差异、分析软件的缺乏、数据未能有效空间化等原因,空间点格局分析作为应用地理领域的重要分支,并没有得到地理领域的重视(Gatrell et al, 1996)。近年来,随着地理信息系统技术的发展,空间点格局分析重新受到关注,在空间流行病学(Gatrell et al, 1996)、生态学(Perry et al, 2006)等领域得到了广泛的应用,并形成了大量的点格局分析、建模、可视化工具集,如:SpPack(Perry, 2004)、Geoda(Anselin et al, 2006)、SaTScan(Coleman et al, 2009)等。
在点格局分析中,假设点要素为平面上随机点过程。然而,点要素所在的地理空间并不能总满足欧氏距离下连续空间的假设。例如,顾客不可能直接通过欧氏距离抵达沿街商店,而必须通过路径距离沿着道路抵达商店。因此,连续平面空间的假设对于分析二维空间的子空间来说条件过于苛刻,传统的空间分析方法不一定适用于网络约束要素的分析(Miller, 1999)。网络点要素格局的定性分析可追溯到罗马人依据罗马道路的走向选择殖民地,网络点要素格局的定量分析则出现在Snow(1855)绘制的伦敦沿着Broad街和Golden广场的霍乱分布地图。然而,由于街道网络数据的缺乏、计算机管理和分析技术的不足,网络约束点格局的研究一直比较匮乏(Shiode et al, 2013)。随着GIS和几何计算的发展,对于网络约束点格局的发展逐渐取得进展(Toussaint, 1985; Maguire et al, 1991),得到了地理学家、物理学家、社会学家的高度重视,形成了GeoDaNet、SANET工具包,并展开了系列应用(Okabe et al, 2006; Boots et al, 2007; Yamada et al, 2007; Borgatti et al, 2009; Sugihara et al, 2011; Okabe et al, 2012; Jiang et al, 2014)。特别是,在新兴数据获取技术和多样数据分析工具的推动下,subarea-based(meso-scale)的传统经验空间分析方法,正在逐渐向更小尺度的object-based(micro-scale)空间分析过度(Okabe et al, 2012),而从宏观尺度到微观尺度过度的重要标志则是二维或三维欧氏空间中的网络约束点格局分析,对网络约束点要素进行分析和表达是地理信息科学研究中的主要问题之一(Batty, 2005)。
3.3.1 网络一阶分析方法
核密度估计方法作为空间点格局分析的重要方法,逐渐被拓展到网络空间,并在网络约束点格局一阶分析中得到了广泛应用。Flahaut等(2003)率先设计了一种基于简单网络的核密度估计方法,但是其网络复杂度相对较低;随后,Borruso(2005)也提出基于网络距离密度函数的核密度估计方法,并证实该方法可以定位网络上的线性聚类,并可更精确表达网络约束要素的分布模式,但是该方法对网络自身及网络所在的区域依赖性较高。同样,Downs等(2007a, 2007b)通过两个网络核密度估计的案例应用,充分阐释了网络核密度估计在解决网络约束问题的优越性,其一是将城市道路网络的交叉口网络密度作为城市中心性的度量指标,其二是通过分析动物移动轨迹网络来估算动物居所的范围。Xie等(2008)证实网络约束核密度估计方法比传统的平面核密度估计方法更适合分析网络约束要素,并将其应用到交通事故分析中,还指出核密度估计中剖分粒度和搜索半径的重要性。由于缺少关于核密度估计值偏差的讨论,Nie等(2015)将道路网络进行等距离划分,使用一种组合式的网络核密度估计方法进行点格局分析,弥补了核密度估计方法缺少统计检验的不足;Okabe等(2009)定了三种不同类型的核函数,即网络普通核函数、网络连续核函数、网络非连续核函数,不仅对不同核函数估计值的偏差和计算复杂度进行度量,而且形成了基于GIS的网络核密度估计工具用以辅助应用,但是提出的三种核函数却不可以同时保证估计无偏,同时全部满足其提出的七种属性,如,核中心对称、等距离、等密度等。随后,Sugihara等(2010)又对equal-split核函数进行了修正,从而满足了网络短环路情况下的无偏性。
随着网络核密度估计方法的优势逐渐体现,学者们开始尝试将网络核密度的方法应用到城市地理学方面。Yu等(2015)采用网络核密度方法对城市中心商业区进行分析和界定;Timothée等(2010)采用网络核密度方法对零售店和金融服务活动进行分析,提出了人类活动密度指标,将该指标修正为可以表征城市中心的网络性能的重要参数。Lachance-Bernard等(2011)用网络核密度方法探测卢布尔雅那地区的自行车热点位置,从而辅助规划者进行自行车设施的最优化配置。Rui等(2016)使用网络核密度方法对城市尺度的沿街零售业热点区域进行探测,并对品牌的零售店进行聚类分析,从而为新零售店的最优选址提供参考。
此外还有一些其他网络点格局一阶分析方法的相关研究。例如,Steenberghen等(2010)将网络分割成不同的统计单元,使用网络距离度量空间点要素的空间邻近度,计算每个空间单元上的点要素聚集情况,并使用蒙特卡洛方法对聚类的统计显著性进行评价。
3.3.2 网络点格局二阶分析方法研究
网络点格局的二阶分析方法主要是度量空间点要素的局部偏差与空间交互结构。 Goodchild(1986)认为网络空间自相关的度量有以下两种情况:一种是使用网络弧段值代表两个节点间某变量的相似性度量,变量可以是城市、区域、乡村或者其他空间单元,这种情况与传统空间自相关分析相似,Doreian(1990)通过使用社会变量表示个体和社会网络的链接,用社会网络自相关案例进行了实证分析;另一种是链自身属性值的空间自相关,也就是真正意义的自相关,其权重矩阵反映链的连通、链的邻接、网络距离。Black(1992)也认为空间自相关和网络自相关是两种不同的现象,空间自相关的邻居是连续空间上用欧氏距离度量的邻居,而网络自相关是网络空间上的用网络距离度量的邻居,首次提出网络自相关的概念,并将Moran'I 方法扩展到网络空间。Yamada(2004)提出了网络约束聚类局部统计量的思想,分别讨论网络空间单个独立要素之间的相关性和网络空间单元本身的非可数的要素之间的相关性。
在网络点格局二阶分析具体的方法层面,Okabe等(1995)首充分考虑点要素自身受网络约束这一特征,提出了离散网络上的随机点过程,即二项点过程、多项点过程、单变量二项点过程、多变量二项点过程,并以此为基础提出了四种统计方法,分析位置因素对网络约束的点分布的影响,即网络Clark-Evans 统计、网络链的属性分类统计、单一设施对点分布的影响分析、多类型设施对点分布的影响分析。随后,Okabe等(2001)又将传统欧氏距离的无限平面K函数方法拓展为最短路径距离的有限网络空间K函数方法,分别提出网络K函数方法和网络交叉K函数方法,并将其应用于沿街快餐店的分布研究中,此项研究表明网络K函数方法不仅理论有效而且计算有效,为网络空间点分布提供了有效的方法。随后,Yamada等(2004)在网络K函数的基础上,提出了局部K函数聚类统计量的计算方法,用来探测网络点事件空间显著性聚类趋势,并用以美国Buffalo地区高速公路机动车碰撞分布进行实例分析。Yamada等(2010)人进一步将平面Moran's I统计和平面G统计扩展成为网络空间的Moran's I统计和G统计。在此基础上,学者们开展了网络点格局分析二阶方法优化与实例验证,如:使用网络K函数进行沿街医院和药店格局的探测(Ni et al, 2016)、结合分层贝叶斯方法和网络局部聚类探测方法进行沿街兴趣点的分析(Wang et al, 2017)。
3.3.3 其他网络点格局分析方法
除了上述网络约束点格局分析的研究外,学者们将其他空间点格局分析方法进行网络空间扩展。在网络点格局聚类分析方面,Shiode(2008)提出网络样方方法进行网络约束点的聚类分析,通过计算并比较平面样方、网络样方结果的χ2统计值、Moran's I统计值,结果表明平面样方方法常常过度估计了空间格局的扩散态势,网络样方方法则可以通过网络样方聚类基本单元,更高效地刻画微观尺度数据,但是考虑到计算的复杂度,该方法仅在小地域范围内进行测试;此后,Shiode(2011)提出了基于街道网的时空分析方法和基于街道网空间扫描统计方法,并通过模拟数据和真实数据证实了该方法在监测街道级犯罪热点上具有更高的精度、敏感性、稳定性;近年来,Shiode等(2013)又提出了采用网络约束时空搜索窗的方法对街道尺度下犯罪事件热点进行探测,不仅大大拓展了网络时空分析方法的框架,而且能够更准确地检测街道尺度下点要素在时间和空间上的聚集。在网络泰森多边形方面,Okabe等(2008)提出了加权网络Voronoi图的概念,用向内距离、向外距离分别进行加法、乘法加权最短路径距离,奠定了网络泰森多边形的理论基础,使得加权网络Voronoi图的方法逐渐推广应用到基于位置服务的最近邻查询上;艾廷华 等(2013)提出了一种基于水流扩展的网络泰森多边形生成模型,用网络栅格单元长度为步长,以点为源头让水流沿着网络蔓延,充分考虑了网络图结构中的多种约束;She等(2015)结合网络核密度估计方法和网络聚类局部统计量方法提出了两种改进式的网络权重泰森多边形的应用思想,充分考虑了网络约束点的分布格局对资源分配的影响。在网络空间插值方面,Shiode等(2011)将平面空间插值中的反距离权重插值和普通克里金插值扩展到网络空间,并用两种不同的网络格局对这两种方法进行交叉验证,比较均方误差之后发现:网络插值方法对边界效应的更敏感,网络插值方法的稳定性受样本点的个数影响较大,但可通过边界修正进行优化。在聚类分析方面,Sugihara等(2011)首次建立了基于网络约束的分层聚类的框架,提出采用不同距离度量方式,如最近邻对距离、最远对距离、平均距离、中值对距离、半径距离等的网络分层聚类方法,可根据聚类过程的需要或时间复杂度的需要选择合适的网络分层方式。
机动车碰撞,是最典型的网络约束点现象,其空间格局及形成过程的定量化研究是交通及其交叉学科的研究热点,点格局分析在机动车碰撞中主要应用体现在机动车碰撞整体和局部格局分布探测(即热点探测)。
早期的交通事故研究中,学者们使用空间汇总数据的方式将交通事故分散到道路路段上,分别统计每个路段上交通事故的数目从而得到事故黑点。根据路段划分的方式不同,分为等距离路段划分和非等距离路段划分两种观点。研究表明,路段长度影响空间汇总数据分析的结果,路段长度的选择即是采用地理学方法分析交通事故中的可塑性面积单元问题。从统计验证的角度来说,等距离划分的方法更适用,学者们采用该方法进行了一系列对交通事故进行研究,如cell-count方法(使每段路上拥有一定数量的事故数)、equal-size方法(讨论等长度路段上的事故数量)等(Black, 1992)。在实际研究过程中,由于道路网络的节点和其链接的复杂性,等长度剖分道路网络常常会造成一些不满足基本道路长度的破碎路段,卢佩莹 等(2011)提出了使用阈值的方法尝试解决等长度剖分中的短路段的问题。无论是等距离划分还是非等距离划分都是将事故数量作为汇总数据单元属性值,对于此类空间统计单元的属性值的分析通常采用空间自相关的方法,为探测道路网络约束交通事故点要素的空间聚集性,学者们提出使用统计指数来表示交通事故的网络空间自相关(Black et al, 1998; Yamada et al, 2010)。
由于汇总数据带来的可塑性面积单元问题,随着GIS技术对事故获取方法的改善,学者们尝试是用非汇总数据,即单个事故数据,来研究道路网络上的交通事故问题(Loo, 2006)。非汇总数据交通事故分析的方法主要有四种:核密度估计方法、最邻近距离法、K函数法、聚类分析法。核密度方法采用钟形的密度函数产生密度表面,从而得到每个位置的事故密度值。Sabel等(2005)采用平面核密度估计方法研究了新西兰Christchurch地区的事故分布情况;Erdogan等(2008)也提出了使用GIS技术研究土耳其Afyokarahisar地区交通事故情况,并使用核密度估计方法进行热点判断。Anderson(2009)结合核密度估计方法和K均值聚类的方法对英国伦敦地区1999-2003年的事故热点进行判别,取得了很好的实际效果。为解决平面核密度估计方法的不足,Xie等(2008)提出了使用网络核密度估计的方法;为解决网络核密度估计方法的统计显著性检验的缺乏,Xie等(2013)又提出使用局部统计对网络核密度估计结果进行评价的思路;Bíl等(2013)则提出了分别对核密度估计结果进行聚类强度和聚类稳定性评价。同时,Loo等(2011)也使用基于GIS的网络约束核密度估计方法对上海市的交通事故进行分析。最邻近距离法则是通过统计每个点周围最邻近距离的事故数量,从而对事故黑点位置进行评价。Black(1991)首次使用最邻近距离对时空区域的交通事故进行分析,Steenberghen等(2004)修正了最邻近距离分析方法,在每个事故点定义一个网络距离半径,并统计该点的事故指数。K函数方法即是对最近邻距离的扩展,其应用也比较广泛(Jones et al, 1996;Yamada et al, 2004)。网络点聚类分析,为空间聚类分析的扩展,Yiu等(2004)提出了网络聚类分析的重要性,并建立了网络聚类分析的算法和数据结构;同样地,Clauset等(2008)提出了网络点的分层聚类分析。
犯罪事件是具有固定地理位置的一类典型的城市点事件,采用空间分析方法解决犯罪问题是犯罪学的重要分支,也是地理学应用的重要方面。研究表明,犯罪事件并不是随机发生的,其倾向于在某些特定地方的集聚,而集聚地可解释为犯罪机会较大的区域或受害者与犯罪者频繁交互的区域(Cohen et al, 1979; Chainey et al, 2005)。通过对犯罪事件的进行格局分析,可了解犯罪的空间分布并定位犯罪热点(hot-spots),有利于警力的调配,进而可以高效地进行犯罪预防和犯罪侦察。目前,许多学者进行了关于犯罪事件的点格局研究,并形成了很多GIS-based的犯罪空间分析工具,包括商业化的软件包,如CrimeStat等,以及基于GIS平台的插件,如CRIMEVIEW等。最早的犯罪点格局分布研究出现在19世纪的法国,犯罪地图是犯罪信息可视化、犯罪事件分析的载体;随着计算机技术和GIS技术的发展,关于犯罪分布的研究得到了广泛的关注和发展,并相继成立专门的犯罪事件空间分布研究机构进行犯罪类城市点事件的地理学分析。同时,犯罪事件点格局的表达方法也从单纯性的点图、变量符号图、等值线图转变为可以表达时间和空间变化的动画图、3D图,分析方法也从传统的缓冲分析、标准误差椭圆等估计方法拓展到核密度估计、时空分析层面。McEwen等(1995)提出采用点图的三种基本的特性(描述、分析、交互)对犯罪事件进行描述和定位,但是该方法在处理相同位置多起事件的时候容易出现符号重叠。Goldsmith等(1999)提出在犯罪点事件数据量大的时候,采用核密度估计的方法可以更高效的进行热点探测。Brunsdon等(2007)提出并证实采用map animation方法、comap方法、isosurface方法对犯罪事件进行时空分析和可视化的可行性,并建议将该方法进一步推广到其他城市空间点事件的分析过程。Chainey等(2008)以犯罪历史数据为实验数据,采用人口普查区专题地图、空间椭圆、网格专题制图、核密度估计四种方法分别生成汽车盗窃、街头犯罪、车辆盗窃等热点地图,并估测不同方法生成的热点图的预测精度,结果表明核密度估计方法在分析不同类型犯罪事件中预测结果均最优。随着空间分析尺度从区域级或城市级向更精细化的街道级或者社区级发展,在街区级或街道网级的进行犯罪事件的空间格局分析即采用网络约束点格局方法进行犯罪事件分析,逐渐成为犯罪学微观分析的重要方面(Weisburd et al, 2009)。譬如,Lu等(2007)认为采用平面K函数的方法对网络约束下的城市活动进行空间自相关格局分析时,存在着一些误报问题,并提出使用网络K函数的方法对城市机动车盗窃案进行分析。Shiode(2011)提出使用基于街道级的时空犯罪分析和空间扫描统计方法探测毒品事件、抢劫事件的犯罪热点,进而提出基于网络时空搜索窗的方法研究犯罪点事件(Shiode et al, 2013)。Tompson等(2009)提出了一种热路段的方法对网络上的犯罪风险分布进行度量,该方法通过计算每个路段的犯罪率实现热点的判断。
点格局分析不仅仅广泛应用于交通事故分析中,而且逐渐应用于其他网络约束点要素的分析。在生态学上,Spooner等(2004)使用网络核函数方法研究澳大利亚洛克哈特夏尔地区的刺槐种群分布;在城市路网研究方面,Furth等(2000)对公交线路上的公交站点距离进行分析。广义的网络上点包括建筑物内廊道的点和复杂设施上的通道上的点,一些学者尝试高层建筑内部的网络通行路径分析(Kwan et al, 2005)。
沿街分布的点要素在现实中非常普遍,特别在在城市区域,如沿街商店。Yu等(2015)使用网络核密度估计对城市沿街ATM机的分布进行探测,根据分布情况对城市商业区进行评价;禹文豪等(2015)对网络空间下的POI进行可视化与分析;佘冰等(2015)以网络约束的方法分析城市占道经营情况,从而提出合理的城市设施布局。Sevtsuk(2010)对英国剑桥和萨默维尔地区的零售店和食品店的分布进行了分析;Myint(2008)对美国诺曼市的银行、快餐店、学校、教堂等的分布进行分析。
丝绸之路也是典型的网络空间,学者们也尝试研究受丝绸之路约束的点要素分布情况。譬如,Li等(1990)研究了中国西北地区的丝绸之路沿线城市人口中血红蛋白异常分布;Xie等(2007)研究了丝绸之路的河西走廊中部的古城市分布。
综上所述,网络约束现象作为地理环境中一种较为常见的现象,逐渐得到了地理学界和各交叉学科研究者的关注。计量地理学、几何地理学等领域的发展,促进了网络约束理论的发展,一方面对传统的欧氏平面空间分析模型进行了网络改进和优化;另一方面对特定的网络约束问题提出了新的算法和模型。同时,网络约束应用分析也取得了一系列的研究成果,特别是在运用网络空间点格局分析进行交通事故黑点(区)、犯罪热点探测和分析方面的研究。但是,网络约束空间分析模型及方法依然存在着诸多不完善之处,以下分别从方法层面和应用层面讨论目前网络约束空间点格局研究中需要进一步解决和研究的问题。
在宏观方法层面,目前,虽然已经有些学者尝试研究网络约束点要素的空间特性,并努力将平面空间模型扩展到网络空间,以解决网络约束空间问题。但是,当前的网络约束点要素的研究主要是以某一类型要素为例,将某一种平面空间分析方法进行网络空间扩展,一方面讨论其方法的有效性,另一方面揭露该类点要素的网络分布特征,但鲜有学者针对某类网络约束点要素问题采用系统化的空间分析框架进行网络约束点要素的空间格局分布探测。在具体的方法层面,应进一步讨论不同类型网络空间权重矩阵对网络空间模型性能的影响,定量地讨论不同基本单元长度、搜索半经、研究尺度对网络空间模型性能的影响,寻找针对不同研究区域的最优模型参数尺度,进一步加强时空网络空间模型的构建,如时空网络核密度估计、时空网络局部空间统计方法等,探索网络空间约束点格局的时空变化。
针对某一典型应用,在空间格局的识别上,可从空间角度对点要素与网络情况进行多尺度分析,分别讨论微观尺度和宏观尺度下两者的相互作用;在格局成因探索上,可讨论对网络约束点格局及其影响因素的交互作用。以城市道路网络为例,需对更多类型的点要素的格局进行探测,从而综合评价道路沿线土地利用、社会经济情况;同时,应特别关注地理环境因素、土地利用因素、交通流量、路网通达性等对网络空间点格局的影响,并进行定量研究。
The authors have declared that no competing interests exist.
| [60] |
Geographic information analysis [M]. |
| [61] |
SpPack: Spatial point pattern analysis in Excel using Visual Basic for Applications (VBA) [J].https://doi.org/10.1016/j.envsoft.2003.07.004 URL [本文引用: 1] 摘要
Many different sciences have developed many different tests to describe and characterise spatial point data. For example, all the trees in a given area may be mapped such that their x , y co-ordinates and other variables, or ‘marks’, (e.g. species, size) might be recorded. Statistical techniques can be used to explore interactions between events at different length scales and interactions between different types of events in the same area. SpPack is a menu-driven add-in for Excel written in Visual Basic for Applications (VBA) that provides a range of statistical analyses for spatial point data. These include simple nearest-neighbour-derived tests and more sophisticated second-order statistics such as Ripley’s K -function and the neighbourhood density function (NDF). Some simple grid or quadrat-based statistics are also calculated. The application of the SpPack add-in is demonstrated for artificially generated event sets with known properties and for a multi-type ecological event set.
|
| [62] |
A comparison of methods for the statistical analysis of spatial point patterns in plant ecology [J].https://doi.org/10.1007/s11258-006-9133-4 URL [本文引用: 1] 摘要
We describe a range of methods for the description and analysis of spatial point patterns in plant ecology. The conceptual basis of the methods is presented, and specific tests are compared, with the goal of providing guidelines concerning their appropriate selection and use. Simulated and real data sets are used to explore the ability of these methods to identify different components of spatial pattern (e.g. departure from randomness, regularity vs. aggregation, scale and strength of pattern). First-order tests suffer from their inability to characterise pattern at distances beyond those at which local interactions (i.e. nearest neighbours) occur. Nevertheless, the tests explored (first-order nearest neighbour, Diggle’s G and F ) are useful first steps in analysing spatial point patterns, and all seem capable of accurately describing patterns at these (shorter) distances. Among second-order tests, a density-corrected form of the neighbourhood density function (NDF), a non-cumulative analogue of the commonly used Ripley’s K -function, most informatively characterised spatial patterns at a range of distances for both univariate and bivariate analyses. Although Ripley’s K is more commonly used, it can give very different results to the NDF because of its cumulative nature. A modified form of the K -function suitable for inhomogeneous point patterns is discussed. We also explore the use of local and spatially-explicit methods for point pattern analysis. Local methods are powerful in that they allow variations from global averages to be detected and potentially provide a link to recent spatial ecological theory by taking the 65plant’s-eye view’. We conclude by discussing the problems of linking spatial pattern with ecological process using three case studies, and consider some ways that this issue might be addressed.
|
| [63] |
Modelling spatial patterns [J]. |
| [64] |
A stochastic analysis of the spatial clustering of retail establishments [J].https://doi.org/10.1080/01621459.1965.10480853 URL [本文引用: 1] 摘要
Abstract The tendency for particular retail establishments to cluster has been noted by several theorists on the subject of intraurban retail spatial structure. Hotelling, for example, in his classical essay on spatial competition, concludes that as “more and more sellers of the same commodity arise, the tendency is not to become distributed in the socially optimum manner but to cluster unduly.” Rolph and Proudfoot provide empirical evidence of this tendency, and Nelson supplies a rationale for it by his “principle of cumulative attraction.” The analysis of the spatial clustering of particular categories of retail establishments has received considerable attention in the literature on intraurban retail spatial structure. However, the efforts thus far have not provided a readily utilizable means for investigating interurban and temporal differentials. A pioneering effort in this direction is a study by Roland Artle which, though very rudimentary, is the first reference system proposed with quantitative comparisons in mind. Artie begins by gridding the central area of Stockholm into a net of 210 squares, 250 meters on a side, and counts the number of retail establishments in each square for each of six selected categories of merchandise groups. He then studies the deviation of the resulting distributions from that which could be expected under the assumption of a random (i.e., Poisson) distribution. The analysis of spatial clustering described below is an attempt to generalize and extend Artie's schema and indeed utilizes his data for purposes of empirical verification.
|
| [65] |
Network-constrained and category-based point pattern analysis for Suguo retail stores in Nanjing, China [J].https://doi.org/10.1080/13658816.2015.1080829 URL 摘要
The distribution of many geographical objects and events is affected by the road network; thus, network-constrained point pattern analysis methods are helpful to understand their space structures and distribution patterns. In this study, network kernel density estimation and network K-function are used to study retail service hot-spot areas and the spatial clustering patterns of a local retail giant (Suguo), respectively, in Nanjing city. Stores and roads are categorized to investigate the influence of weighting different categories of point events and network on the analysis. In addition, the competitive relation between Suguo and foreign-brand retail chains was revealed. The comprehensive analysis results derived from the combination of the first-order and second-order properties can be further used to examine the reasonability of the existing store distribution and optimize the locational choice of new stores.
|
| [66] |
Road traffic accident simulation modeling: A kernel estimation approach [C]
|
| [67] |
Path and place: A study of urban geometry and retail activity in Cambridge and Somerville, MA [D]. |
| [68] |
Weighted network Voronoi Diagrams for local spatial analysis [J].https://doi.org/10.1016/j.compenvurbsys.2015.03.005 URL [本文引用: 1] 摘要
Detection of spatial clusters among geographic events in a planar space often fails in real world practices. For example, events in urban areas often occurred on or along streets. In those cases, objects and their movements were limited to the street network in the urban area. This deviated from what a set of freely located points could represent. Consequently, many of the spatial analytic tools would likely produce biased results. To reflect this limitation, we developed a new approach, weighted network Voronoi diagrams, to modeling spatial patterns of geographic events on street networks whose street segments can be weighted based on their roles in the events. Using kernel density estimation and local Moran index statistics, the frequency of events occurring on a street segment can be used to produce a weight to associate with the street segment. The weights can then be normalized using a predefined set of intervals. The constructed weighted Voronoi network explicitly takes into account the characteristics of how events distribute, instead of being limited to assessing the spatial distribution of events without considering how the structure of a street network may affect the distribution. This approach was elaborated in a case study of Wuhan City, China. Constructing weighted network Voronoi diagrams of these partitioned networks could assist city planners and providers of public/private services to better plan for network-constrained service areas.
|
| [69] |
Street-level spatial interpolation using network-based IDW and ordinary kriging [J].https://doi.org/10.1111/j.1467-9671.2011.01278.x URL [本文引用: 1] 摘要
Abstract This study proposes network-based spatial interpolation methods to help predict unknown spatial values along networks more accurately. It expands on two of the commonly used spatial interpolation methods, IDW (inverse distance weighting) and OK (ordinary kriging), and applies them to analyze spatial data observed on a network. The study first provides the methodological framework, and it then examines the validity of the proposed methods by cross-validating elevations from two contrasting patterns of street network and comparing the MSEs (Mean Squared Errors) of the predicted values measured with the two proposed network-based methods and their conventional counterparts. The study suggests that both network-based IDW and network-based OK are generally more accurate than their existing counterparts, with network-based OK constantly outperforming the other methods. The network-based methods also turn out to be more sensitive to the edge effect, and their performance improves after edge correction. Furthermore, the MSEs of standard OK and network-based OK improve as more sample locations are used, whereas those of standard IDW and network-based IDW remain stable regardless of the number of sample locations. The two network-based methods use a similar set of sample locations, and their performance is inherently affected by the difference in their weight distribution among sample locations.
|
| [70] |
Analysis of a distribution of point events using the network-based quadrat method [J].https://doi.org/10.1111/j.0016-7363.2008.00735.x URL [本文引用: 1] 摘要
This study proposes a new quadrat method that can be applied to the study of point distributions in a network space. While the conventional planar quadrat method remains one of the most fundamental spatial analytical methods on a two-dimensional plane, its quadrats are usually identified by regular, square grids. However, assuming that they are observed along a network, points in a single quadrat are not necessarily close to each other in terms of their network distance. Using planar quadrats in such cases may distort the representation of the distribution pattern of points on a network. The network-based units used in this article, on the other hand, consist of subsets of the actual network, providing more accurate aggregation of the data points along the network. The performance of the network-based quadrat method is compared with that of the conventional quadrat method through a case study on a point distribution on a network. The 2 statistic and Moran's I statistic of the two quadrat types indicate that (1) the conventional planar quadrat method tends to overestimate the overall degree of dispersion and (2) the network-based quadrat method derives a more accurate estimate on the local similarity. The article also performs sensitivity analysis on network and planar quadrats across different scales and with different spatial arrangements, in which the abovementioned statistical tendencies are also confirmed.
|
| [71] |
Street-level spatial scan statistic and STAC for analysing street crime concentrations [J].https://doi.org/10.1111/j.1467-9671.2011.01255.x URL [本文引用: 1] 摘要
This study develops new types of hotspot detection methods to describe the micro-space variation of the locations of crime incidents at the street level. It expands on two of the most widely used hotspot detection methods, Spatial and Temporal Analysis of Crime and Spatial Scan Statistic, and applies them to the analysis of the network space. The study first describes the conceptual and the methodological framework of the new methods followed by analyses using: (1) a simulated distribution of points along the street network; and (2) real street-crime incident data. The simulation study using simulated point distributions confirms that the proposed methods is more accurate, stable and sensitive in detecting street-level hotspots than their conventional counterparts are. The empirical analysis with real crime data focuses on the distribution of the drug markets and robberies in downtown Buffalo, NY in 1995 and 1996. The drug markets are found to form hotspots that are dense, compact and stable whereas hotspots of the robberies are observed more thinly across a wider area. The study also reveals that the location of the highest risk remains on the same spot over time for both types of crimes, indicating the presence of hotbeds which requires further attention.
|
| [72] |
Network-based space-time search-window technique for hotspot detection of street-level crime incidents [J].https://doi.org/10.1080/13658816.2012.724175 URL [本文引用: 3] 摘要
This study proposes a street-level space‐time hotspot detection method to analyse crime incidents recorded at the street-address level and provides description of the micro-level variation of crime incidents over space and time. It expands the notion of search-window techniques widely used in crime science by developing a method that can account for the spatial‐temporal distribution of crime incidents measured in network distance. The study first describes the methodological framework by presenting the concept of a new type of search window and how it is used in the process of statistical testing for detecting crime hotspots. This is followed by analyses using (1) a simulated distribution of points along the street network, and (2) a set of real street-crime incident data. The simulation study demonstrates that the proposed method is effective in identifying space‐time hotspots, which include those that are not detected by a non-temporal method. The empirical analysis of the drug markets and assaults in downtown Buffalo, New York, revealed a detailed space‐time signature of each type of crime, highlighting the recurrent nature of drug dealing at specific locations as well as the sporadic tendency of assault incidents.
|
| [73] |
On the mode of communication of cholera [M].
|
| [1] |
水流扩展思想的网络空间Voronoi图生成 [J].
Voronoi图是地理空间设施分布特征提取的重要几何模型,基于不同的空间距离概念可建立不同的Voronoi图。本研究顾及城市网络空间中设施点的服务功能及相互联系发生于网络路径距离而非传统的欧式距离的事实,针对网络空间Voronoi图模型,建立一种网络空间Voronoi图生成的栅格扩展算法。首先对图结构的边目标剖分为细小的线性单元,称作网络空间的栅格化,引入水流扩展思想,将事件点发生源视为“水源”,以栅格单元长度为扩展步长,让水流方向沿着网络上的可通行路径同时向外蔓延,直至与其他水流相遇或者到达边的尽头。该算法可方便地加入网络图结构中的多种约束,如街道边的单向行驶、结点的限制性连接等实际空间限制条件。通过大规模实际数据的“数字城市”POI点服务范围的试验表明该算法的效率高。
Algorithm for constructing network Voronoi diagram based on flow extension ideas [J].
Voronoi图是地理空间设施分布特征提取的重要几何模型,基于不同的空间距离概念可建立不同的Voronoi图。本研究顾及城市网络空间中设施点的服务功能及相互联系发生于网络路径距离而非传统的欧式距离的事实,针对网络空间Voronoi图模型,建立一种网络空间Voronoi图生成的栅格扩展算法。首先对图结构的边目标剖分为细小的线性单元,称作网络空间的栅格化,引入水流扩展思想,将事件点发生源视为“水源”,以栅格单元长度为扩展步长,让水流方向沿着网络上的可通行路径同时向外蔓延,直至与其他水流相遇或者到达边的尽头。该算法可方便地加入网络图结构中的多种约束,如街道边的单向行驶、结点的限制性连接等实际空间限制条件。通过大规模实际数据的“数字城市”POI点服务范围的试验表明该算法的效率高。
|
| [74] |
Spatial analysis of roadside Acacia populations on a road network using the network K-function [J].https://doi.org/10.1023/B:LAND.0000036114.32418.d4 URL [本文引用: 1] 摘要
Spatial patterning of plant distributions has long been recognised as being important in understanding underlying ecological processes. Ripley K-function is a frequently used method for studying the spatial pattern of mapped point data in ecology. However, application of this method to point patterns on road networks is inappropriate, as the K-function assumes an infinite homogenous environment in calculating Euclidean distances. A new technique for analysing the distribution of points on a network has been developed, called the network K-function (for univariate analysis) and network cross K-function (for bivariate analysis). To investigate its applicability for ecological data-sets, this method was applied to point location data for roadside populations of three Acacia species in a fragmented agricultural landscape of south-eastern Australia. Kernel estimations of the observed density of spatial point patterns for each species showed strong spatial heterogeneity. Combined univariate and bivariate network K-function analyses confirmed significant clustering of populations at various scales, and spatial patterns of Acacia decora suggests that roadworks activities may have a stronger controlling influence than environmental determinants on population dynamics. The network K-function method will become a useful statistical tool for the analyses of ecological data along roads, field margins, streams and other networks.
|
| [75] |
Spatial clustering of events on a network [J].https://doi.org/10.1016/j.jtrangeo.2009.08.005 URL [本文引用: 1] 摘要
In this paper a methodology is proposed to compute spatial concentrations of point-based events on a network. The distance along the network is used as a measure of the spatial closeness of events. The network is divided into statistical units, based on a random distribution of points of measurement and corresponding network segments, which are the statistical units of reference. For each segment a dangerousness index is computed which indicates the distance-weighted number of traffic accidents in the neighbourhood. The statistical significance of clusters of accidents is tested using a Monte Carlo simulation. The methodology is applied to traffic accidents to detect dangerous locations on the road network of the city of Brussels in Belgium.
|
| [2] |
基于GIS的道路热区鉴别方法 [J].URL 摘要
基于地理信息系统以及热区基本模型,研究了道路热区的鉴别方法。该方法对道路网依据一定优先权进行合并以获取道路基本单元,模拟了交通事故的空间分布,并采用Monte Carlo法定义各道路基本单元交通事故数阈值,通过检验道路基本单元的空间邻近性得到热区,并对上海世博园周边道路热区进行了鉴别。分析结果表明:道路网经合并后,不规则道路基本单元的百分比由41.5%下降到14.8%;世博园周边共有84个仅涉及车辆、33个涉及行人的热区,与实际相符。可见,该方法能有效鉴别道路危险区域。
Identification method of road hot zone based on GIS [J].URL 摘要
基于地理信息系统以及热区基本模型,研究了道路热区的鉴别方法。该方法对道路网依据一定优先权进行合并以获取道路基本单元,模拟了交通事故的空间分布,并采用Monte Carlo法定义各道路基本单元交通事故数阈值,通过检验道路基本单元的空间邻近性得到热区,并对上海世博园周边道路热区进行了鉴别。分析结果表明:道路网经合并后,不规则道路基本单元的百分比由41.5%下降到14.8%;世博园周边共有84个仅涉及车辆、33个涉及行人的热区,与实际相符。可见,该方法能有效鉴别道路危险区域。
|
| [76] |
Intra-urban location and clustering of road accidents using GIS: A Belgian example [J].https://doi.org/10.1080/13658810310001629619 URL 摘要
This paper aims to show the usefulness of GIS and point pattern techniques for defining road-accident black zones within urban agglomerations. The location of road accidents is based on dynamic segmentation, address geocoding and intersection identification. One-dimensional (line) and two-dimensional (area) clustering techniques for road accidents are compared. Advantages and drawbacks are discussed in relation to network and traffic characteristics. Linear spatial clustering techniques appear to be better suited when traffic flows can be clearly identified along certain routes. For dense road networks with diffuse traffic patterns, two-dimensional techniques make it possible to identify accident-prone areas. The operationality of the techniques is illustrated by showing the impact of traffic-calming measures on the location and type of accidents in one Belgian town (Mechelen).
|
| [77] |
Computational method for the point cluster analysis on networks [J].https://doi.org/10.1007/s10707-009-0092-5 URL [本文引用: 2] 摘要
We present a general framework of hierarchical methods for point cluster analysis on networks, and then consider individual clustering procedures and their time complexities defined by typical variants of distances between clusters. The distances considered here are the closest-pair distance, the farthest-pair distance, the average distance, the median-pair distance and the radius distance. This paper will offer a menu for users to choose hierarchical clustering algorithms on networks from a time complexity point of view.
|
| [3] |
|
| [78] |
Simple and unbiased kernel function for network analysis [C]
|
| [79] |
A network based kernel density estimator applied to Barcelona economic activities [C]
|
| [4] |
道路网约束下的事件时空交互检验方法研究 [J].Test methods for space-time interaction of events under road network constraints [J]. |
| [80] |
Hot routes: Developing a new technique for the spatial analysis of crime [J].URL 摘要
The use of hotspot mapping techniques such as KDE to represent the geographical spread of linear events can be problematic. Network-constrained data (for example transport-related crime) require a different approach to visualize concentration. We propose a methodology called Hot Routes, which measures the risk distribution of crime along a linear network by calculating the rate of crimes per section of road. This method has been designed for everyday crime analysts, and requires only a Geographical Information System (GIS), and suitable data to calculate. A demonstration is provided using crime data collected from London bus routes.
|
| [81] |
Computational geometry [M]. |
| [5] |
地理学时空数据分析方法 [J].https://doi.org/10.11821/dlxb201409007 URL [本文引用: 1] 摘要
随着地理空间观测数据的多年积累,地球环境、社会和健康数据监测能力的增强,地理信息系统和计算机网络的发展,时空数据集大量生成,时空数据分析实践呈现快速增长。本文对此进行了分析和归纳,总结了时空数据分析的7类主要方法,包括:时空数据可视化,目的是通过视觉启发假设和选择分析模型;空间统计指标的时序分析,反映空间格局随时间变化;时空变化指标,体现时空变化的综合统计量;时空格局和异常探测,揭示时空过程的不变和变化部分;时空插值,以获得未抽样点的数值;时空回归,建立因变量和解释变量之间的统计关系;时空过程建模,建立时空过程的机理数学模型;时空演化树,利用空间数据重建时空演化路径。通过简述这些方法的基本原理、输入输出、适用条件以及软件实现,为时空数据分析提供工具和方法手段。
Spatiotemporal data analysis in geography [J].https://doi.org/10.11821/dlxb201409007 URL [本文引用: 1] 摘要
随着地理空间观测数据的多年积累,地球环境、社会和健康数据监测能力的增强,地理信息系统和计算机网络的发展,时空数据集大量生成,时空数据分析实践呈现快速增长。本文对此进行了分析和归纳,总结了时空数据分析的7类主要方法,包括:时空数据可视化,目的是通过视觉启发假设和选择分析模型;空间统计指标的时序分析,反映空间格局随时间变化;时空变化指标,体现时空变化的综合统计量;时空格局和异常探测,揭示时空过程的不变和变化部分;时空插值,以获得未抽样点的数值;时空回归,建立因变量和解释变量之间的统计关系;时空过程建模,建立时空过程的机理数学模型;时空演化树,利用空间数据重建时空演化路径。通过简述这些方法的基本原理、输入输出、适用条件以及软件实现,为时空数据分析提供工具和方法手段。
|
| [82] |
Drumlins: Their distribution, orientation, and morphology [J].https://doi.org/10.1111/j.1541-0064.1971.tb00147.x URL [本文引用: 1] 摘要
First page of article
|
| [83] |
Analysis of the spatial variation of network-constrained phenomena represented by a link attribute using a hierarchical Bayesian model [J].https://doi.org/10.3390/ijgi6020044 URL [本文引用: 1] 摘要
The spatial variation of geographical phenomena is a classical problem in spatial data analysis and can provide insight into underlying processes. Traditional exploratory methods mostly depend on the planar distance assumption, but many spatial phenomena are constrained to a subset of Euclidean space. In this study, we apply a method based on a hierarchical Bayesian model to analyse the spatial variation of network-constrained phenomena represented by a link attribute in conjunction with two experiments based on a simplified hypothetical network and a complex road network in Shenzhen that includes 4212 urban facility points of interest (POIs) for leisure activities. Then, the methods named local indicators of network-constrained clusters (LINCS) are applied to explore local spatial patterns in the given network space. The proposed method is designed for phenomena that are represented by attribute values of network links and is capable of removing part of random variability resulting from small-sample estimation. The effects of spatial dependence and the base distribution are also considered in the proposed method, which could be applied in the fields of urban planning and safety research.
|
| [6] |
|
| [84] |
Putting crime in its place: Units of analysis in geographic criminology [M]. |
| [85] |
The urban system in West China: A case study along the mid-section of the ancient Silk Road-He-Xi Corridor [J].https://doi.org/10.1016/j.cities.2006.11.006 URL [本文引用: 1] 摘要
The evolution of the urban system in the semi-arid and arid West China has a close relationship to the origin, prosperity, and decline of the ancient Silk Road. This urban system bears noticeable inscriptions of the fragile physical environment, complex ethnic mix, and changing political systems and policies. This paper uses the mid-section of the ancient Silk Road He-Xi Corridor as a case study to examine the challenges of urban development in West China and to propose suggestions for future development from the perspective of comprehensive planning. The research focuses on a series of seven cities and numerous towns which primarily serve the local population by providing different functions, beyond their value to travelers and historians. These cities are rapidly gaining importance to provincial and national authorities. Although current political, social, and economic influences are significant, a considerable part of their evolution can be explained by the natural environment, primary resources, ethnic differences, and their geographical distributions. The investigation examines the relationship between the evolution of these urban centers and internal and external conditions and provides a base for planning policy to enhance their viability as significant nodes for future development.
|
| [7] |
核密度估计法支持下的网络空间POI点可视化与分析 [J].https://doi.org/10.11947/j.AGCS.2015.20130538 Magsci [本文引用: 1] 摘要
<p>城市空间POI点的分布模式、分布密度在基础设施规划、城市空间分析中具有重要意义, 表达该特征的核密度法(kernel density estimation)由于顾及了地理学第一定律的区位影响,比其他密度表达方法(如样方密度、基于Voronoi图密度)占优.然而,传统的核密度计算方法往往基于二维延展的欧氏空间,忽略了城市网络空间中设施点的服务功能及相互联系发生于网络路径距离而非欧氏距离的事实.本研究针对该缺陷,给出了网络空间核密度计算模型,分析了核密度方法在置入网络结构中受多种约束条件的扩展模式,讨论了衰减阈值及高度极值对核密度特征表达的影响.通过实际多种POI点分布模式(随机型、稀疏型、区域密集型、线状密集型)下的核密度分析试验,讨论了POI基础设施在城市区域中的分布特征、影响因素、服务功能.</p>
The visualization and analysis of POI features under network space supported by kernel density estimation [J].https://doi.org/10.11947/j.AGCS.2015.20130538 Magsci [本文引用: 1] 摘要
<p>城市空间POI点的分布模式、分布密度在基础设施规划、城市空间分析中具有重要意义, 表达该特征的核密度法(kernel density estimation)由于顾及了地理学第一定律的区位影响,比其他密度表达方法(如样方密度、基于Voronoi图密度)占优.然而,传统的核密度计算方法往往基于二维延展的欧氏空间,忽略了城市网络空间中设施点的服务功能及相互联系发生于网络路径距离而非欧氏距离的事实.本研究针对该缺陷,给出了网络空间核密度计算模型,分析了核密度方法在置入网络结构中受多种约束条件的扩展模式,讨论了衰减阈值及高度极值对核密度特征表达的影响.通过实际多种POI点分布模式(随机型、稀疏型、区域密集型、线状密集型)下的核密度分析试验,讨论了POI基础设施在城市区域中的分布特征、影响因素、服务功能.</p>
|
| [86] |
Kernel density estimation of traffic accidents in a network space [J].https://doi.org/10.1016/j.compenvurbsys.2008.05.001 URL 摘要
A standard planar Kernel Density Estimation (KDE) aims to produce a smooth density surface of spatial point events over a 2-D geographic space. However, the planar KDE may not be suited for characterizing certain point events, such as traffic accidents, which usually occur inside a 1-D linear space, the roadway network. This paper presents a novel network KDE approach to estimating the density of such spatial point events. One key feature of the new approach is that the network space is represented with basic linear units of equal network length, termed lixel (linear pixel), and related network topology. The use of lixel not only facilitates the systematic selection of a set of regularly spaced locations along a network for density estimation, but also makes the practical application of the network KDE feasible by significantly improving the computation efficiency. The approach is implemented in the ESRI ArcGIS environment and tested with the year 2005 traffic accident data and a road network in the Bowling Green, Kentucky area. The test results indicate that the new network KDE is more appropriate than standard planar KDE for density estimation of traffic accidents, since the latter covers space beyond the event context (network space) and is likely to overestimate the density values. The study also investigates the impacts on density calculation from two kernel functions, lixel lengths, and search bandwidths. It is found that the kernel function is least important in structuring the density pattern over network space, whereas the lixel length critically impacts the local variation details of the spatial density pattern. The search bandwidth imposes the highest influence by controlling the smoothness of the spatial pattern, showing local effects at a narrow bandwidth and revealing hot spots at larger or global scales with a wider bandwidth. More significantly, the idea of representing a linear network by a network system of equal-length lixel s may potentially lead the way to developing a suite of other network related spatial analysis and modeling methods.
|
| [87] |
Detecting traffic accident clusters with network kernel density estimation and local spatial statistics: An integrated approach [J].https://doi.org/10.1016/j.jtrangeo.2013.05.009 URL 摘要
Kernel density estimation (KDE) has long been used for detecting traffic accident hot spots and network kernel density estimation (NetKDE) has proven to be useful in accident analysis over a network space. Yet, both planar KDE and NetKDE are still used largely as a visualization tool, due to the missing of quantitative statistical inference assessment. This paper integrates NetKDE with local Moran’I for hot spot detection of traffic accidents. After density is computed for road segments through NetKDE, it is then used as the attribute for computing local Moran’s I. With an NetKDE-based approach, conditional permutation, combined with a 100-m neighbor for Moran’s I computation, leads to fewer statistically significant “high-high” (HH) segments and hot spot clusters. By conducting a statistical significance analysis of density values, it is now possible to evaluate formally the statistical significance of the extensiveness of locations with high density values in order to allocate limited resources for accident prevention and safety improvement effectively.
|
| [8] |
Kernel density estimation and K-means clustering to profile road accident hotspots [J].https://doi.org/10.1016/j.aap.2008.12.014 URL PMID: 19393780 摘要
Identifying road accident hotspots is a key role in determining effective strategies for the reduction of high density areas of accidents. This paper presents (1) a methodology using Geographical Information Systems (GIS) and Kernel Density Estimation to study the spatial patterns of injury related road accidents in London, UK and (2) a clustering methodology using environmental data and results from the first section in order to create a classification of road accident hotspots. The use of this methodology will be illustrated using the London area in the UK. Road accident data collected by the Metropolitan Police from 1999 to 2003 was used. A kernel density estimation map was created and subsequently disaggregated by cell density to create a basic spatial unit of an accident hotspot. Appended environmental data was then added to the hotspot cells and using K-means clustering, an outcome of similar hotspots was deciphered. Five groups and 15 clusters were created based on collision and attribute data. These clusters are discussed and evaluated according to their robustness and potential uses in road safety campaigning.
|
| [9] |
GeoDa: An introduction to spatial data analysis [J].https://doi.org/10.1111/j.0016-7363.2005.00671.x URL [本文引用: 1] 摘要
Abstract This article presents an overview of GeoDa, a free software program intended to serve as a user-friendly and graphical introduction to spatial analysis for non-geographic information systems (GIS) specialists. It includes functionality ranging from simple mapping to exploratory data analysis, the visualization of global and local spatial autocorrelation, and spatial regression. A key feature of GeoDa is an interactive environment that combines maps with statistical graphics, using the technology of dynamically linked windows. A brief review of the software design is given, as well as some illustrative examples that highlight distinctive features of the program in applications dealing with public health, economic development, real estate analysis, and criminology.
|
| [88] |
Analysis of spatial clusters when the phenomenon is constrained by a network space [D]. |
| [89] |
Comparison of planar and network K-functions in traffic accident analysis [J].https://doi.org/10.1016/j.jtrangeo.2003.10.006 URL 摘要
The network and planar K -function methods are applied to traffic accident data to illustrate the risk of false positive detection associated with the use of a statistic designed for a planar space to analyze a network-constrained phenomenon. We also demonstrate the benefits of using a method specifically designed for a network space. The results clearly indicate that the planar K -function analysis is problematic since it entails a significant chance of over-detecting clustered patterns. Analyses are implemented based on Monte Carlo simulation and applied to 1997 traffic accident data in the Buffalo, NY area.
|
| [10] |
Interactive spatial data analysis [M]. |
| [11] |
The statistical analysis of spatial pattern [M]. |
| [90] |
Local indicators of network-constrained clusters in spatial point patterns [J].https://doi.org/10.1111/j.1538-4632.2007.00704.x URL [本文引用: 1] 摘要
Abstract The detection of clustering in a spatial phenomenon of interest is an important issue in spatial pattern analysis. While traditional methods mostly rely on the planar space assumption, many spatial phenomena defy the logic of this assumption. For instance, certain spatial phenomena related to human activities are inherently constrained by a transportation network because of our strong dependence on the transportation system. This article thus introduces an exploratory spatial data analysis method named l ocal i ndicators of n etwork-constrained c luster s (LINCS), for detecting local-scale clustering in a spatial phenomenon that is constrained by a network space. The LINCS method presented here applies to a set of point events distributed over the network space. It is based on the network K -function, which is designed to determine whether an event distribution has a significant clustering tendency with respect to the network space. First, an incremental K -function is developed so as to identify cluster size more explicitly than the original K -function does. Second, to enable identification of cluster locations, a local K -function is derived by decomposing and modifying the original network K -function. The local K -function LINCS, which is referred to as KLINCS, is tested on the distribution of 1997 highway vehicle crashes in the Buffalo, NY area. Also discussed is an adjustment of the KLINCS method for the nonuniformity of the population at risk over the network. As traffic volume can be seen as a surrogate of the population exposed to a risk of vehicle crashes, the spatial distribution of vehicle crashes is examined in relation to that of traffic volumes on the network. The results of the KLINCS analysis are validated through a comparison with priority investigation locations (PILs) designated by the New York State Department of Transportation.
|
| [91] |
Local indicators of network-constrained clusters in spatial patterns represented by a link attribute [J].https://doi.org/10.1080/00045600903550337 URL [本文引用: 2] 摘要
Clustering in a spatially distributed phenomenon is an important focus of spatial analysis because it not only suggests characteristics of the pattern itself but also of its background processes. Traditional methods of spatial cluster detection mostly rely on the planar space assumption, yet a variety of spatial phenomena do not support its logic. This article expounds on an exploratory spatial data analysis methodology named local indicators of networkconstrained clusters (LINCS) introduced elsewhere for detecting local-scale clustering in a spatial phenomenon that is constrained by a network space. In particular, this article focuses on two types of LINCS methods that are network extensions of traditional methods for analyzing spatial associations in zone-based planar-space data, namely, the local Moran I statistic and the local Getis and Ord G statistic. They are designed for phenomena that are represented by attribute values of individual network links. Examples of such phenomena include traffic volume, traffic speed, and the number of vehicle crashes aggregated at the link level. When the phenomenon of interest can be seen as a subset of a more generic spatial phenomenon, for example, vehicle crashes in relation to the entire traffic observed in a study region, the LINCS methods are capable of taking into account the distribution of such a base phenomenon so that one can avoid the detection of spurious clusters merely reflecting the base distribution. The article illustrates the application of the two LINCS methods using data on highway vehicle crashes in the Buffalo, New York, area in 1997. 空间分布现象的聚类分析是空间分析的重点,因为这不不仅表明该模式本身也表明其后台进程的特征。空间群检 测的传统方法主要是依赖于平面空间的假设,但很多空间现象不支持其逻辑。本文阐述了名为本地网络约束簇指 标(LINCS) 的空间数据分析方法。此方法在其它领域用于检测受限于网络空间的空间分布现象的本地级聚类。 本文特别重点介绍两种类型的LINCS 方法,即传统方法网络扩展类型,用于分析区域空间为基础的平面空间数 据的空间关系。IlP 本地的Moran 1 统计和本地的Getis 和OrdG 统计。它们被用于表示个体网络链接属性值的空间 现象, 包括交通流量、交通速度和链接级聚合的交通车祸的数目。当感兴趣的现象可以视为一个更通用的空间现象的子集时,例如,交通车祸相对于研究地区观察到的整个交通情况时, L剧CS 方法能够考虑到此基本现象之 分布而使我们得以避免那些只反映出基本分布的虚假群集的检测。本文阐释两种使用1997纽约州布法罗地区高速 公路车祸数据的LINCS方法的应用。并锺就: $苦笑岔抑, 平曾胁Moran I !tJ Getis & Ord ~结讶, 在必却挥分,于,用 绥空颅,李捞。 El agolpamiento [clustering] en un fenómeno distribuido espacialmente es un importante enfoque en análisis espacial porque tal condición no solo sugiere características del propio patrón, sino también de sus procesos de base. Los métodos tradicionales de detección de agrupamiento espacial se basan principalmente en el supuesto del espacio plano, si bien una variedad de fenómenos espaciales no vindican su lógica. Este artículo se adentra en una metodología exploratoria de análisis de datos espaciales denominada indicadores locales de agrupamientos de redes constre09idas (LINCS, por el acrónimo en inglés), presentada en otra parte como método para detectar agrupamientos a escala local de un fenómeno espacial que es constre09ido por un espacio de redes. Este artículo enfoca en particular dos tipos de métodos LINCS que son extensiones en red de métodos tradicionales para analizar asociaciones espaciales en datos de espacio plano de base zonal, a saber, la estadística local Moran y la estadística local Getis y Ord G. Estos métodos se dise09aron para estudiar fenómenos que están representados por valores de atributo de los eslabones individuales de una red. Los ejemplos de tales fenómenos incluyen cosas como el volumen de tráfico, velocidad del tráfico y el número de colisiones vehiculares agregadas al nivel del eslabón. Cuando el fenómeno que interesa puede visualizarse como un subconjunto de un fenómeno espacial más genérico, por ejemplo, colisiones de vehículos en relación con el tráfico conjunto observado en una región de estudio, los métodos LINCS son capaces de tomar en cuenta la distribución de tal fenómeno base, de modo que uno pueda evitar la detección de agrupamientos espurios que tan solo reflejan la distribución de base. El artículo ilustra la aplicación de los dos métodos LINCS mediante el uso de datos sobre colisiones de vehículos en carretera en el área de Buffalo, Nueva York, en 1997.
|
| [12] |
Network geography: Relations, interactions, scaling and spatial processes in GIS [M] |
| [13] |
Identification of hazardous road locations of traffic accidents by means of kernel density estimation and cluster significance evaluation [J].https://doi.org/10.1016/j.aap.2013.03.003 URL PMID: 23567216 摘要
This paper proposes a procedure which evaluates clusters of traffic accident and organizes them according to their significance. The standard kernel density estimation was extended by statistical significance testing of the resulting clusters of the traffic accidents. This allowed us to identify the most important clusters within each section. They represent places where the kernel density function exceeds the significance level corresponding to the 95th percentile level, which is estimated using the Monte Carlo simulations. To show only the most important clusters within a set of sections, we introduced the cluster strength and cluster stability evaluation procedures. The method was applied in the Southern Moravia Region of the Czech Republic.
|
| [92] |
Clustering objects on a spatial network [C]
|
| [93] |
The analysis and delimitation of central business district using network kernel density estimation [J].https://doi.org/10.1016/j.jtrangeo.2015.04.008 URL [本文引用: 1] 摘要
Central Business District (CBD) is the core area of urban planning and decision management. The cartographic definition and representation of CBD is of great significance in studying the urban development and its functions. In order to facilitate these processes, the Kernel Density Estimation (KDE) is a very efficient tool as it considers the decay impact of services and allows the enrichment of the information from a very simple input scatter plot to a smooth output density surface. However, most existing methods of density analysis consider geographic events in a homogeneous and isotropic space under Euclidean space representation. Considering the case that the physical movement in the urban environment is usually constrained by a street network, we propose a different method for the delimitation of CBD with network configurations. First, starting from the locations of central activities, a concentration index is presented to visualize the functional urban environment by means of a density surface, which is refined with network distances rather than Euclidean ones. Then considering the specialties of network distance computation problem, an efficient way supported by flow extension simulation is proposed. Taking Shenzhen and Guangzhou, two quite developed cities in China as two case studies, we demonstrate the easy implementation and practicability of our method in delineating CBD.
|
| [14] |
Highway accidents: A spatial and temporal analysis [J].URL 摘要
A temporal, spatial, and spatial-temporal autocorrelation analysis of highway accidents on the Indiana Toll Road from 1983 to 1987 is presented. Applications of von Neumann's ratio, Moran's I, nearest-neighbor analysis, and a spatial-temporal autocorrelation coefficient to a transportation network situation are illustrated. Applications of these methods to transport network attributes, such as accidents, have not appeared previously. The main objectives are to determine whether these techniques are sensitive enough to distinguish different patterns in the accident distributions and whether these patterns are explainable. The analysis involved 10 sets of accident data, categorized by date of occurrence and location on an east-west roadway. Only 2 of the 10 revealed positive temporal autocorrelation (clustering in time), 5 revealed positive spatial autocorrelation (clustering in space), and between 6 and 9, depending on the method used, revealed positive spatial-temporal autocorrelation (clustering in time and space). These results suggest that observed autocorrelations in accidents are a function of weather conditions or traffic volumes, or a combination of the two.
|
| [15] |
Network autocorrelation in transport network and flow systems [J].https://doi.org/10.1111/j.1538-4632.1992.tb00262.x URL [本文引用: 1] 摘要
The use of Moran's I to assess the existence of network autocorrelation in flows over the arcs of real (tangible) and abstract (intangible) networks is examined. Residuals of a migration model developed here reveal the presence of such autocorrelation or dependence. Two approaches for removing the observed dependence are examined.
|
| [16] |
Accidents on belgium's motorways: A network autocorrelation analysis [J].https://doi.org/10.1016/S0966-6923(97)00037-9 URL [本文引用: 1] 摘要
A method of assessing the extent to which the value of a variable on a given segment of a network influences values of that variable on contiguous segments is examined here. The method uses network autocorrelation analysis, a network variant of spatial autocorrelation analysis, and Moran's I statistic to make the assessment. Illustrations of positive and negative network autocorrelation are given and interpreted for several simple linear networks. An empirical sampling distribution for the case of a ten link network is derived based on 100000 samples; this distribution is compared with a normal distribution and found not to be significantly different. Use of network autocorrelation analysis with more complex networks is demonstrated using 1991 motor vehicle accident rates for a portion of the motorway network of Belgium. A significant level of positive network autocorrelation is observed. It is further demonstrated that the source of the observed positive covariation can be identified using a secondary analysis that focuses on the motorway and ring road components of the overall system to identify those portions of the network that are the major sources of the positive autocorrelation. A further analysis reveals that the major sources of this positive covariation have been properly identified.
|
| [17] |
Local statistical spatial analysis: Inventory and prospect [J].https://doi.org/10.1080/13658810601034267 URL [本文引用: 1] 摘要
The past decade has witnessed extensive development of measures that examine characteristics of spatial subsets (local spaces) defined with respect to a complete data set (global space). Such procedures have evolved independently in fields such as geography, GIS, cartography, remote sensing, and landscape ecology. Collectively, we label these procedures as local spatial methods. We focus on those methods that share a common goal of identifying subsets whose characteristics are statistically 'significant' in some way. We propose the concept of local spatial statistical analysis (LoSSA) both as an integrative structure for existing methods and as a framework that facilitates the development of new local and global statistics. By formalizing what is involved when a particular local statistic is used, LoSSA helps to reveal the key features and limitations of the procedure. These include a consideration of the nature of the spatial subsets, their spatial relationship to the complete data set, and the relationship between a given global statistic and the corresponding local statistics computed for the data set.
|
| [18] |
Network analysis in the social sciences [J].https://doi.org/10.1126/science.1165821 URL PMID: 19213908 [本文引用: 1] 摘要
Abstract Over the past decade, there has been an explosion of interest in network research across the physical and social sciences. For social scientists, the theory of networks has been a gold mine, yielding explanations for social phenomena in a wide variety of disciplines from psychology to economics. Here, we review the kinds of things that social scientists have tried to explain using social network analysis and provide a nutshell description of the basic assumptions, goals, and explanatory mechanisms prevalent in the field. We hope to contribute to a dialogue among researchers from across the physical and social sciences who share a common interest in understanding the antecedents and consequences of network phenomena.
|
| [19] |
Network density estimation: Analysis of point patterns over a network [M]
|
| [20] |
Visualising space and time in crime patterns: A comparison of methods [J].https://doi.org/10.1016/j.compenvurbsys.2005.07.009 URL 摘要
Previous research exploring space–time patterns has focused on the relative merits and drawbacks of the effectiveness of static maps vis-à-vis interactive dynamic visualisation techniques. In particular, they have tended to concentrate on the role of animation in interpretation of patterns and the understanding of underlying factors influencing such patterns. The aim of this paper is to broaden this debate out to consider the effectiveness of a wider range of visualisation techniques in permitting an understanding of spatio-temporal trends. The merits of three visualisation techniques, (map animation, the comap and the isosurface) are evaluated on their ability to assist in the exploration of space–time patterns of crime disturbance data. We conclude that each technique has some merit for crime analysts charged with studying such trends but that further research is needed to apply the techniques to other sources of crime data (and to other sectors such as health) to permit a comprehensive evaluation of their respective strengths and limitations as exploratory visualisation tools.
|
| [21] |
|
| [22] |
GIS and crime mapping [M]. |
| [23] |
The utility of hotspot mapping for predicting spatial patterns of crime [J].https://doi.org/10.1057/palgrave.sj.8350066 URL |
| [24] |
Hierarchical structure and the prediction of missing links in networks [J].
|
| [25] |
Social change and crime rate trends: A routine activity approach [J].https://doi.org/10.2307/2094589 URL [本文引用: 1] 摘要
In this paper we present a "routine activity approach" for analyzing crime rate trends and cycles. Rather than emphasizing the characteristics of offenders, with this approach we concentrate upon the circumstances in which they carry out predatory criminal acts. Most criminal acts require convergence in space and time of likely offenders, suitable targets and the absence of capable guardians against crime. Human ecological theory facilitates an investigation into the way in which social structure produces this convergence, hence allowing illegal activities to feed upon the legal activities of everyday life. In particular, we hypothesize that the dispersion of activities away from households and families increases the opportunity for crime and thus generates higher crime rates. A variety of data is presented in support of the hypothesis, which helps explain crime rate trends in the United States 1947-1974 as a byproduct of changes in such variables as labor force participation and single-adult households.
|
| [26] |
Using the SaTScan method to detect local malaria clusters for guiding malaria control programmes [J].https://doi.org/10.1186/1475-2875-8-68 URL PMID: 19374738 [本文引用: 1] 摘要
Mpumalanga Province, South Africa is a low malaria transmission area that is subject to malaria epidemics. SaTScan methodology was used by the malaria control programme to detect local malaria cluster
|
| [27] |
Statistics for spatial data [M]. |
| [28] |
|
| [29] |
Network autocorrelation models: Problems and prospects [M] |
| [30] |
Characterising linear point patterns [C]
|
| [31] |
Network-based kernel density estimation for home range analysis [C]
|
| [32] |
Geographical information systems aided traffic accident analysis system case study: City of Afyonkarahisar [J].https://doi.org/10.1016/j.aap.2007.05.004 URL PMID: 18215546 摘要
Geographical Information System (GIS) technology has been a popular tool for visualization of accident data and analysis of hot spots in highways. Many traffic agencies have been using GIS for accident analysis. Accident analysis studies aim at the identification of high rate accident locations and safety deficient areas on the highways. So, traffic officials can implement precautionary measures and provisions for traffic safety. Since accident reports are prepared in textual format in Turkey, this situation makes it difficult to analyze accident results. In our study, we developed a system transforming these textual data to tabular form and then this tabular data were georeferenced onto the highways. Then, the hot spots in the highways in Afyonkarahisar administrative border were explored and determined with two different methods of Kernel Density analysis and repeatability analysis. Subsequently, accident conditions at these hot spots were examined. We realized that the hot spots determined with two methods reflect really problematic places such as cross roads, junction points etc. Many of previous studies introduced GIS only as a visualization tool for accident locations. The importance of this study was to use GIS as a management system for accident analysis and determination of hot spots in Turkey with statistical analysis methods.
|
| [33] |
The local spatial autocorrelation and the kernel method for identifying black zones: A comparative approach [J].https://doi.org/10.1016/S0001-4575(02)00107-0 URL PMID: 12971934 摘要
This article aims to determine the location and the length of road sections characterized by a concentration of accidents (black zones). Two methods are compared: one based on a local decomposition of a global autocorrelation index, the other on kernel estimation. After explanation, both methods are applied and compared in terms of operational results, respective advantages and shortcomings, as well as underlying conceptual elements. The operationality of both methods is illustrated by an application to one Belgian road.
|
| [34] |
Optimal bus stop spacing through dynamic programming and geographic modeling [J].https://doi.org/10.3141/1731-03 URL [本文引用: 1] 摘要
A discrete approach was used to model the impacts of changing bus-stop spacing on a bus route. Among the impacts were delays to through riders, increased operating cost because of stopping delays, and shorter walking times perpendicular to the route. Every intersection along the route was treated as a candidate stop location. A simple geographic model was used to distribute the demand observed at existing stops to cross-streets and parallel streets in the route service area, resulting in a demand distribution that included concentrated and distributed demands. An efficient, dynamic programming algorithm was used to determine the optimal bus-stop locations. The model was compared with the continuum approach used in previous studies. A bus route in Boston was modeled, in which the optimal solution was an average stop spacing of 400 m (4 stops/mi), in sharp contrast to the existing average spacing of 200 m (8 stops/mi). The model may also be used to evaluate the impacts of adding, removing, or relocating selected stops.
|
| [35] |
|
| [36] |
Spatial point pattern analysis and its application in geographical epidemiology [J].https://doi.org/10.2307/622936 URL [本文引用: 2] 摘要
This paper reviews a number of methods for the exploration and modelling of spatial point patterns with particular reference to geographical epidemiology (the geographical incidence of disease). Such methods go well beyond the conventional 'nearest-neighbour' and 'quadrat' analyses which have little to offer in an epidemiological context because they fail to allow for spatial variation in population density. Correction for this is essential if the aim is to assess the evidence for 'clustering' of cases of disease. We examine methods for exploring spatial variation in disease risk, spatial and space-time clustering, and we consider methods for modelling the raised incidence of disease around suspected point sources of pollution. All methods are illustrated by reference to recent case studies including child cancer incidence, Burkitt's lymphoma, cancer of the larynx and childhood asthma. An Appendix considers a range of possible software environments within which to apply these methods. The links to modern geographical information systems are discussed.
|
| [37] |
Analyzing crime patterns: Frontiers of practice [M].
|
| [38] |
Spatial autocorrelation: Concepts and techniques in modern geography [M]. |
| [39] |
Different ways of thinking about street networks and spatial analysis [J].https://doi.org/10.1111/gean.12060 URL [本文引用: 1] 摘要
Street networks, as one of the oldest infrastructures of transport in the world, play a significant role in modernization, sustainable development, and human daily activities in both ancient and modern times. Although street networks have been well studied in a variety of engineering and scientific disciplines, including for instance transport, geography, urban planning, economics, and even physics, our understanding of street networks in terms of their structure and dynamics remains limited, especially when dealing with such real-world problems as traffic jams, pollution, and human evacuations for disaster management. One goal of this special issue is to promote different ways of thinking about understanding street networks, and of conducting spatial analysis.
|
| [40] |
The application of K-function analysis to the geographical distribution of road traffic accident outcomes in Norfolk, England [J]. |
| [41] |
A quantitative expression of the pattern of urban settlements in selected areas of the United States [J]. |
| [42] |
Emergency response after 9/11: The potential of real-time 3D GIS for quick emergency response in micro-spatial environments [J].https://doi.org/10.1016/j.compenvurbsys.2003.08.002 URL [本文引用: 1] 摘要
Terrorist attacks at the World Trade Center (WTC) in New York City and the Pentagon on September 11, 2001, not only affected multi-level structures in urban areas but also impacted upon their immediate environment at the street level in ways that considerably reduced the speed of emergency response. In this paper, we examine the potential of using real-time 3D GIS for the development and implementation of GIS-based intelligent emergency response systems (GIERS) that aim at facilitating quick emergency response to terrorist attacks on multi-level structures (e.g. multi-story office buildings). We outline a system architecture and a network data model that integrates the ground transportation system with the internal conduits within multi-level structures into a navigable 3D GIS. We examine important implementation issues of GIERS, especially the need for wireless and mobile deployment. Important decision support functionalities of GIERS are also explored with particular reference to the application of network-based shortest path algorithms. Finally, we present the results of an experimental implementation of an integrated 3D network data model using a GIS database of Franklin County, Ohio (USA). Our study shows that response delay within multi-level structures can be much longer than delays incurred on the ground transportation system, and GIERS have the potential for considerably reducing these delays.
|
| [43] |
Network based kernel density estimation for cycling facilities optimal location applied to Ljubljana [C]
|
| [44] |
Abnormal hemoglobins in the Silk Road region of China [J].https://doi.org/10.1007/BF00197711 URL PMID: 2265836 [本文引用: 1] 摘要
A review is presented of the occurrence of 24 abnormal hemoglobins (13 alpha-chain variants and 11 beta-chain variants) in populations in the Silk Road area of Northwestern China. Most frequently occurring were Hb D-Punjab [beta 121(GH4)Glu----Gln] in Uygurs, Kazaks, and Khalkhas, Hb G-Taipei [beta 22(B4)Glu----Gly] in persons of the Han nationality, and Hb G-Coushatta [beta 22 (B4)Glu----Ala] in the Uygurs, Kazaks, Hans, and related nationalities. The data suggest that these variants likely originated in Central Asia, in the Han nationality of China, and in the minorities of northern China, respectively. Other variants occurred at considerably lower frequencies and were imported from other countries or arose as independent mutations. Two variants [Hb Tashikuergan or alpha 19(AB1)Ala----Glu; Hb Tianshui or beta 39(C5) Gln----Arg] were observed for the first time. The data from this study of the many variants support the movements of various populations in this area, as reported in numerous historical documents.
|
| [45] |
Validating crash locations for quantitative spatial analysis: A GIS-based approach [J].https://doi.org/10.1016/j.aap.2006.02.012 URL PMID: 16574045 [本文引用: 1] 摘要
In this paper, the spatial variables of the crash database in Hong Kong from 1993 to 2004 are validated. The proposed spatial data validation system makes use of three databases (the crash, road network and district board databases) and relies on GIS to carry out most of the validation steps so that the human resource required for manually checking the accuracy of the spatial data can be enormously reduced. With the GIS-based spatial data validation system, it was found that about 65鈥80% of the police crash records from 1993 to 2004 had correct road names and district board information. In 2004, the police crash database contained about 12.7% mistakes for road names and 9.7% mistakes for district boards. The situation was broadly comparable to the United Kingdom. However, the results also suggest that safety researchers should carefully validate spatial data in the crash database before scientific analysis.
|
| [46] |
Spatial point analysis of road crashes in Shanghai: A GIS-based network kernel density method [C]
|
| [47] |
On the false alarm of planar K-function when analyzing urban crime distributed along streets [J].https://doi.org/10.1016/j.ssresearch.2006.05.003 URL 摘要
Many social and economic activities, especially those in urban areas, are subject to location restrictions imposed by existing street networks. To analyze the spatial patterns of these urban activities, the restrictions imposed by the street networks need to be taken into account. K -function is a method commonly used for general point pattern analysis as well as crime pattern study. However, applying the planar K -function to analyze the spatial autocorrelation patterns of urban activities that are typically distributed along streets could result in false alarm problems. Depending on the nature of the urban street networks and the distribution of the urban activities, either positive or negative false alarm might be introduced. Acknowledging that many urban crimes are typically distributed along streets, this paper compares the traditional planar K -function with a network K -function for crime pattern analysis. The patterns of vehicle thefts in San Antonio, Texas are examined as a case study.
|
| [48] |
Geographical information systems: Principles and applications [M]. |
| [49] |
|
| [50] |
Measuring space-time accessibility benefits within transportation networks: Basic theory and computational procedures [J].https://doi.org/10.1111/j.1538-4632.1999.tb00408.x URL [本文引用: 1] 摘要
Accessibility is a fundamental but often neglected concept in transportation analysis and planning. Three complementary views of accessibility have evolved in the literature. The first is the constraints-oriented approach, best implemented by Hgerstrand's space-time prisms. The second perspective follows a spatial interaction framework and derives “attraction-accessibility measures” that compare destinations' attractiveness with the travel costs required. A third approach measures the benefit provided to individuals by the transportation land-use system. This paper reconciles the three complementary approaches by deriving space-time accessibility and benefit measures that are consistent with the rigorous Weibull axiomatic framework for accessibility measures. This research also develops computational procedures for calculating these measures within network structures. This provides realistic accessibility measures that reflect the locations, distances, and travel velocities allowed by an urban transportation network. Since their computational burdens are reasonable, they can be applied at the urban scale using a GIS.
|
| [51] |
An exploration of spatial dispersion, pattern, and association of socio-economic functional units in an urban system [J].https://doi.org/10.1016/j.apgeog.2008.02.005 URL [本文引用: 1] 摘要
Hypotheses based on a set of socio-economic, cultural, and political functional units are examined. The geographic techniques employed in the study include spatial mean, standard distance, standard deviational ellipse, nearest neighbor analysis, and spatial analysis on a network: cross K function and network cross K function. The study not only explores the spatial pattern, distribution, and association of key socio-economic, cultural, and political units which could reveal internal structures and activities of an urban system, but also demonstrates a number of operational procedures that permit applications of traditional and advanced spatial analysis approaches in the study of real urban systems.
|
| [52] |
Spatial distribution characteristics of healthcare facilities in Nanjing: Network point pattern analysis and correlation analysis [J].https://doi.org/10.3390/ijerph13080833 URL PMID: 4997519 [本文引用: 1] 摘要
The spatial distribution of urban service facilities is largely constrained by the road network. In this study, network point pattern analysis and correlation analysis were used to analyze the relationship between road network and healthcare facility distribution. The weighted network kernel density estimation method proposed in this study identifies significant differences between the outside and inside areas of the Ming city wall. The results of network K-function analysis show that private hospitals are more evenly distributed than public hospitals, and pharmacy stores tend to cluster around hospitals along the road network. After computing the correlation analysis between different categorized hospitals and street centrality, we find that the distribution of these hospitals correlates highly with the street centralities, and that the correlations are higher with private and small hospitals than with public and large hospitals. The comprehensive analysis results could help examine the reasonability of existing urban healthcare facility distribution and optimize the location of new healthcare facilities.
|
| [53] |
A network-constrained integrated method for detecting spatial cluster and risk location of traffic crash: A case study from Wuhan, China [J].https://doi.org/10.3390/su7032662 URL 摘要
Research on spatial cluster detection of traffic crash (TC) at the city level plays an essential role in safety improvement and urban development. This study aimed to detect spatial cluster pattern and identify riskier road segments (RRSs) of TC constrained by network with a two-step integrated method, called NKDE-GLINCS combining density estimation and spatial autocorrelation. The first step is novel and involves in spreading TC count to a density surface using Network-constrained Kernel Density Estimation (NKDE). The second step is the process of calculating local indicators of spatial association (LISA) using Network-constrained Getis-Ord Gi* (GLINCS). GLINCS takes the smoothed TC density as input value to identify locations of road segments with high risk. This method was tested using the TC data in 2007 in Wuhan, China. The results demonstrated that the method was valid to delineate TC cluster and identify risk road segments. Besides, it was more effective compared with traditional GLINCS using TC counting as input. Moreover, the top 20 road segments with high-high TC density at the significance level of 0.1 were listed. These results can promote a better identification of RRS, which is valuable in the pursuit of improving transit safety and sustainability in urban road network. Further research should address spatial-temporal analysis and TC factors exploration.
|
| [54] |
SANET: A toolbox for spatial analysis on a network [J].https://doi.org/10.1111/j.0016-7363.2005.00674.x URL [本文引用: 1] 摘要
Abstract Top of page Abstract Introduction Components of SANET Functions of the SANET tools Applications Concluding remarks Acknowledgements References This article shows a geographical information systems (GIS)-based toolbox for analyzing spatial phenomena that occur on a network (e.g., traffic accidents) or almost along a network (e.g., fast-food stores in a downtown). The toolbox contains 13 tools: random point generation on a network, the Voronoi diagram, the K -function and cross K -function methods, the unconditional and conditional nearest-neighbor distance methods, the Hull model, and preprocessing tools. The article also shows a few actual analyses carried out with these tools.
|
| [55] |
Generalized network Voronoi diagrams: Concepts, computational methods, and applications [J].https://doi.org/10.1080/13658810701587891 URL [本文引用: 1] 摘要
In the real world, there are many phenomena that occur on a network or alongside a network; for example, traffic accidents on highways and retail stores along streets in an urbanized area. In the literature, these phenomena are analysed under the assumption that distance is measured with Euclidean distance on a plane. This paper first examines this assumption and shows an empirical finding that Euclidean distance is significantly different from the shortest path distance in an urbanized area if the distance is less than 50002m. This implies that service areas in urbanized areas cannot be well represented by Voronoi diagrams defined on a plane with Euclidean distance, termed generalized planar Voronoi diagrams. To overcome this limitation, second, this paper formulates six types of Voronoi diagrams defined on a network, termed generalized network Voronoi diagrams, whose generators are given by points, sets of points, lines and polygons embedded in a network, and whose distances are given by inward/outward distances, and additively/multiplicatively weighted shortest path distances. Third, in comparison with the generalized planar Voronoi diagrams, the paper empirically shows that the generalized network Voronoi diagrams can more precisely represent the service areas in urbanized areas than the corresponding planar Voronoi diagrams. Fourth, because the computational methods for constructing the generalized planar Voronoi diagrams in the literature cannot be applied to constructing the generalized network Voronoi diagrams, the paper provides newly developed efficient algorithms using the ‘extended’ shortest path trees. Last, the paper develops user‐friendly tools (that are included in SANET, a toolbox for spatial analysis on a network) for executing these computational methods in a GIS environment.
|
| [56] |
A kernel density estimation method for networks, its computational method and a GIS-based tool [J].https://doi.org/10.1080/13658810802475491 URL 摘要
We develop a kernel density estimation method for estimating the density of points on a network and implement the method in the GIS environment. This method could be applied to, for instance, finding ‘hot spots’ of traffic accidents, street crimes or leakages in gas and oil pipe lines. We first show that the application of the ordinary two‐dimensional kernel method to density estimation on a network produces biased estimates. Second, we formulate a ‘natural’ extension of the univariate kernel method to density estimation on a network, and prove that its estimator is biased; in particular, it overestimates the densities around nodes. Third, we formulate an unbiased discontinuous kernel function on a network. Fourth, we formulate an unbiased continuous kernel function on a network. Fifth, we develop computational methods for these kernels and derive their computational complexity; and we also develop a plug‐in tool for operating these methods in the GIS environment. Sixth, an application of the proposed methods to the density estimation of traffic accidents on streets is illustrated. Lastly, we summarize the major results and describe some suggestions for the practical use of the proposed methods.
|
| [57] |
Spatial analysis along networks: Statistical and computational methods [M]. |
| [58] |
The K-function method on a network and its computational implementation [J].https://doi.org/10.1111/j.1538-4632.2001.tb00448.x URL 摘要
Abstract This paper proposes two statistical methods, called the network K-function method and the network cross K-function method, for analyzing the distribution of points on a network. First, by extending the ordinary K-function method defined on a homogeneous infinite plane with the Euclidean distance, the paper formulates the K-function method and the cross K-function method on a finite irregular network with the shortest-path distance. Second, the paper shows advantages of the network K-function methods, such as that the network K-function methods can deal with spatial point processes on a street network in a small district, and that they can exactly take the boundary effect into account. Third, the paper develops the computational implementation of the network K-functions, and shows that the computational order of the K-function method is O(n 2 Q log n Q ) and that of the network cross K-function is O(n Q log U3Q), where n Q is the number of nodes of a network.
|
| [59] |
Statistical analysis of the distribution of points on a network [J].https://doi.org/10.1111/j.1538-4632.1995.tb00341.x URL 摘要
Abstract This paper shows four statistical methods that examine the distribution of points on a network (such as the distribution of retail stores along streets). The first statistical method is an extension of the nearest-neighbor distance method (the Clark-Evans statistic) defined on a plane to the method defined on a network. The second statistical method examines the effect of categorical attribute values of links (say, types of streets) on the distribution of activity points on a network. The third statistical method examines the effect of infrastructural elements (such as railway stations) on the distribution of activity points on a network. The fourth statistical method examines the compound effect of multiple kinds of infrastructural elements (say, railway stations and big parks) on the distribution of activity points on a network. These methods are discussed with empirical examples.
|

/
| 〈 |
|
〉 |
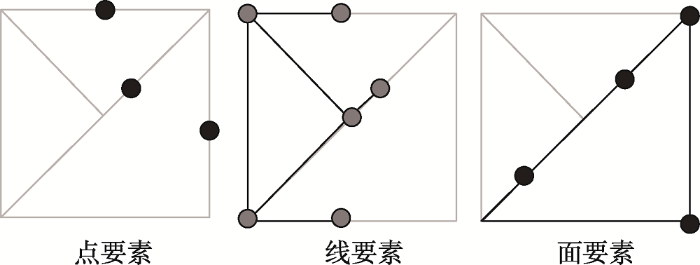
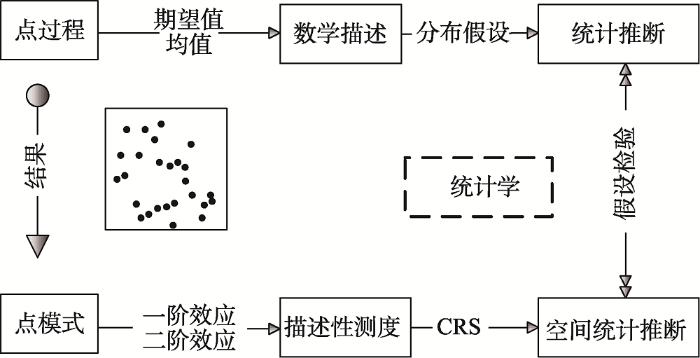
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}