黄正宇 , 陈益强, 刘军发
, 陈益强, 刘军发
HUANG Zhengyu, CHEN Yiqiang, LIU Junfa
通讯作者:
收稿日期: 2016-07-25
修回日期: 2016-09-29
网络出版日期: 2016-11-20
版权声明: 2016 《地球信息科学学报》编辑部 《地球信息科学学报》编辑部 所有
基金资助:
作者简介:
作者简介:黄正宇(1991-),男,湖南岳阳人,硕士生,主要从事室内定位和信息检索方面研究。E-mail: huangzhengyu@ict.ac.cn
展开
摘要
随着WLAN的普及,基于Wi-Fi的室内定位方法逐渐成为研究与应用的热点。虽然,其中基于位置指纹的定位算法研究相对广泛,应用效果较好,然而现有的指纹定位方法或系统仍存在以下3个问题:① 离线阶段的数据标定和定位模型的训练需要耗费大量人力物力,以及时间消耗,使系统很难得到实际应用;② 真实环境中WLAN信号波动呈现高动态性,采集的数据存在显著的时效性,无法提供长时间的有效定位保证;③ 实际环境中AP设备变动频繁,导致训练数据与定位数据特征维度不等长,造成模型失效。针对上述问题,本文提出了一种基于众包数据的模型更新方法,通过不断融合增量数据,使定位模型保持实时有效。该方法主要包括半监督极速学习机(SELM)、具有时效机制的增量式定位方法(TMELM)和特征自适应的在线极速学习机(FA-OSELM)3部分。基于上述方法,本文设计并实现了基于众包数据的室内定位平台系统。实际应用表明,本文提出的方法能够显著降低模型训练阶段的数据采集工作量,有效提升模型训练速度,并且长时间保持较高的定位精度。
关键词:
Abstract
As WLAN getting more and more popular and pervasive, Wi-Fi based indoor localization is becoming a hot issue in research and application fields. Among various kinds of up-to-date indoor localization methods, fingerprint based methods are most widely used because of the good performance. However, the existing fingerprint based methods still have following three common problems: Firstly, fingerprint based methods require a vast amount of calibration work, which need huge human and time consumption both in offline and online phases. It makes the systems difficult to be applied in the practical applications. Secondly, the Wi-Fi signals in the environment change frequently, bringing the significant timeliness in collected data. So it cannot guarantee to provide a long term effective localization. Thirdly, the Wi-Fi access points change frequently in real scene. Thus, the feature dimensions of training data and testing data are unequal. The traditional algorithms cannot well handle the feature dimension changing problem caused by increase or decrease in APs’ number. To solve these problems mentioned above, we proposed a crowdsourcing based indoor localization method, including Semi-supervised ELM, Timeliness Managing ELM and Feature Adaptive Online Sequential ELM. We also developed an indoor localization platform. Applications show that our method can reduce human effort in data calibration and improve the model training speed. Moreover, our method can maintain the high location accuracy for a long time.
Keywords:
基于位置的服务(Location Based Services, LBS)已逐渐成为移动互联网的研究内容热点,基于LBS的应用也随着移动互联网的发展而越来越丰富。近年来,许多定位解决方案不断涌现,如GPS定位、基站定位、地磁定位、超声波定位、射频(RFID)定位、Wi-Fi定位以及基于iBeacon技术的蓝牙定位解决方案等。然而上述定位解决方案均存在其局限性:GPS由于易受到建筑或其他障碍物的阻挡,只适用于室外环境;超声波易受物体遮挡,存在传输受限问题;基于射频的定位方法探测范围较小;iBeacon信号覆盖范围小,需大面积布设,定位局限性较大,成本较高;地磁信号易受电磁干扰而难以精准采集。Wi-Fi具有覆盖面积广、抗干扰能力强、信号稳定以及数据传输速度快和质量高等特点。此外随着智慧城市建设的逐步推进,具备无线通信模块的智能终端逐年普及,日常环境中Wi-Fi信号日渐丰富,无线接入点(Access Point, AP)越来越多,这些都为基于Wi-Fi定位方法的普及实施提供了有利条件。
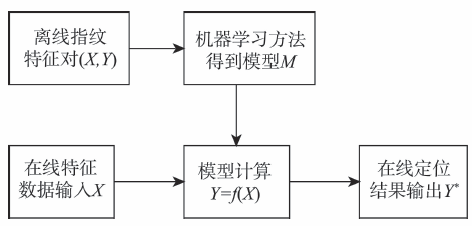
目前,基于Wi-Fi的定位方法主要包含以下4类:基于信号到达时间TOA(Time of Arrival)的定位方法;基于信号到达时间差TDOA(Time difference of Arrival)的定位方法;基于信号到达角度AOA(Angle of Arrive)的定位方法和基于信号强度RSS(Received Signal Strength)的定位方法。由于室内环境复杂,Wi-Fi信号易受障碍物反射,存在严重的多径效应,基于AOA的方法定位精度较低。此外,由于时间精准控制在近距离情况下难以实现,基于TOA和TDOA等定位方法误差过大,实用性差。基于RSS的定位方法因为信号检测装置简单、信号稳定性好以及定位方法简易等特点而受到广泛关注。基于RSS的Wi-Fi室内定位方法又称为位置指纹算法[1],该方法包括离线训练阶段和在线预测阶段,如图1所示。
离线阶段的任务就是大量采集定位区域中各个参考点(Reference Point, RP)的标定指纹数据,然后利用机器学习方法挖掘Wi-Fi信号向量
然而,为了保证定位精度,基于位置指纹的定位方法需要实时更新定位模型,而定位模型的更新需要不断融入新的样本,进而产生了以下3个问题:
(1)样本数据集采集工作量巨大。位置指纹定位算法为保证一定的预测精确度而依赖于大量的训练样本,当样本数据较少时,训练得到的模型无法满足定位精度需求。因此为保证模型预测达到较高的精度,需要耗费大量的人力和物力采集标定数据。在定位系统规模扩大时,大批量的指纹采集将成为一项十分繁重的工作,而采集得到的大量样本也给模型训练和实时预测带来困难。当模型无法在有限时间内快速完成数据训练和预测时,用户体验将会显著下降。
(2)无线信号波动较大,具有明显的时效性特点。基于指纹的定位方法要求用于模型训练的样本数据和在线实时位置估计的测试数据分布具有一致性,当训练数据和测试数据不满足同一分布时,模型的预测精度会出现很大程度的下降。然而在真实环境中,受到时间、空气温湿度、室内环境布局等因素变动的影响,Wi-Fi信号会出现显著的波动,呈现高动态特性。不同因素条件下,扫描终端接收到的AP信号强度和AP个数都会出现明显的变化,从而导致基于前一时间段采集的训练数据得到的预测模型在一段时间后的在线预测阶段适应程度大幅下降。
(3)环境AP呈现高动态性,学习样本和定位样本特征维度不等长。室内环境下Wi-Fi呈现高动态性,一方面体现在Wi-Fi信号强度值的高动态变化,另一方面体现在AP的数量上。因为AP的基本功能是提供智能终端到Internet的桥接,真实环境中部分AP会因为某些原因被移除,新的AP也有可能会部署到环境中。当部分已有AP被移除,信号强度值检测不到或环境中出现新增AP时,均会使特征维度发生变化,即特征维度不等长。传统的指纹定位模型无法对这类情况进行有效处理,只能选择重新训练模型或者忽略新的AP。
针对位置指纹算法在更新模型时遇到的上述问题,本文提出了基于众包(Crowdsourcing)的室内定位方法,即大量引入来自用户的众包增量数据,采用半监督极速学习机(SELM)、具有时效机制的增量式定位方法(TMELM)和特征自适应的在线极速学习机(FA-OSELM),分别从非标定样本应用于模型学习、训练样本时效性以及模型对具有不同特征维度样本的自适应3个角度对问题予以解决,并实现了基于众包数据的室内定位平台系统,取得了较好的应用效果。
本文所引入的半监督极速学习机(SELM)[9]、具有时效机制的增量式定位方法(TMELM)[10]和特征自适应的在线极速学习机(FA-OSELM)[11]均基于极速学习机(Extreme Learning Machine, ELM),本节首先对ELM模型进行简要介绍,接着对SELM、TMELM、FA-OSELM算法模型进行阐述。
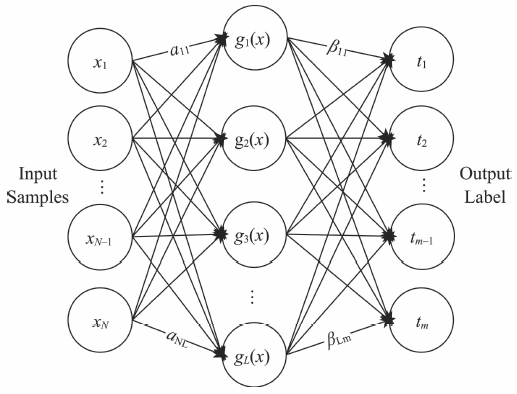
ELM(Extreme Learning Machine)[12-14]属于人工神经网络范畴,是一种单隐层前馈神经网络(Single Hidden Layer Feedforward Neural Network, SLFN)。,该神经网络训练时间短,网络结构较为简洁(图2)。对于一个输入向量
式中:
图2 ELM网络结构(单隐层前馈神经网络SLFN)
Fig. 2 Structure of ELM(Single-hidden layerfeedforward neural networks)
假设
对于输入的
可用矩阵表达为:
根据式(1)可得
根据文献[12]-[14],参数
针对式(4)进行优化,即等价于求解式(6)。
为了保证位置指纹定位算法预测精确度,需要采集大量的标定样本进行模型训练,当样本数据不够时,模型在定位精度上无法满足需求,而人工采集大批量的标定数据工作量巨大。故本文提出众包的采集思路,即用户在使用定位系统的过程中会进行指纹数据采集,通过获取该数据来作为模型更新时的增量训练数据,但这种方式采集到的训练数据为无标定数据。针对该问题,通过引入半监督极速学习机(Semi-supervised ELM, SELM)[9]进行解决。使用SELM能充分利用非标定数据来训练模型,极大地减少标定数据采集的工作量。为了使SELM相比ELM能取得更好的位置预测效果,同时具有很好的泛化能力,根据结构风险最小化理论,模型需要在经验风险和学习函数
由
根据上述,
为了计算方便,可令
进一步可得:
式(7)和式(10)中
对于标定数据集:
(1)通过随机方式来给
(2)计算矩阵H(
(3)计算图的拉普拉斯算子
(4)计算
(5)利用训练得到的模型
在真实环境中,大批量标定数据采集非常困难,而非标定数据的获取比标定数据容易,通过无监督的众包方式,让用户在使用定位系统的过程中实时采集并上传收集到的Wi-Fi指纹数据,进而实时更新训练模型,此方法极大减少了标定数据采集的工作量,训练出来的模型具有很好的泛化能力,在标定数据十分稀疏的情况下也表现良好。
指纹定位模型的预测精度很大程度上由离线阶段的标定数据和在线测试数据是否满足同一分布模型决定,在真实环境中,由于室内的Wi-Fi信号具有高动态性,室内建筑布置格局、空气温湿度以及人流等因素都会引起Wi-Fi信号不同程度的波动。在此情况下,依据采集数据训练出来的模型适应性会显著下降。为了解决模型分布不一致的问题,可引入增量学习框架[20],其特点在于能将最新训练样本实时融入训练模型以达到模型适应环境变化的要求。然而传统增量学习模型框架未对训练样本的时效性加以考虑,采取同等对待方式,导致新模型的适应效果不佳。在3.2中通过半监督学习的方式充分利用了众包方式采集到非标定数据来训练更新位置指纹模型,然而用户不断提交的众包数据具有明显时效差异,不同时间段采集到的无标定数据对当前位置指纹模型的贡献度不一样。通过对新训练样本加以权重[21]考虑,并引入了一种基于时效机制的增量式无线定位方法(Timeliness Managing Extreme Learning Machine, TMELM)[10],可对实时加入的训练数据进行在线增量学习,同时融入时效机制来提高新训练数据对定位模型的贡献,从而保持定位模型的精度。
在增量学习框架中,对于新加入的训练数据
令
从而得到的新模型参数为式(13):
从式(13)可知
惩罚权重
根据3.2讨论,在得到通过用户进行的众包采集无标定数据后,需要将标定数据和非标定数据混合重新训练模型,本节通过引入增量学习方法,只需将非标定数据用于模型训练,从而大大提高了模型的训练速度,同时加入权重考虑,使更新后的模型具有更高的适应度,定位精度长时间保持在较高的水平。
在3.3节中,通过引入时效机制和权重因子解决了众包采集数据因为时间段不同从而贡献度不一致,导致位置指纹模型适应度下降的问题。然而在真实环境中用户会移除部分AP,同时也有可能部署新的AP,由于不同的用户使用定位系统的时间不一致,这样在不同时间段采集到众包数据特征维数不等长,从而导致采集的训练数据、用户提交的无标定增量数据以及实时定位请求数据会出现维度不一致的问题。针对这一问题,本文进一步引入了特征自适应的在线增量极速学习机(Feature Adaptive Online Sequential Extreme Learning Machine, FA-OSELM)[11],当真实环境中AP发生变化导致特征维度改变时,该方法能针对已训练模型的特征维度和新增样本数据特征维度不等长的情况进行自适应调整,从而有效利用新样本数据更新模型,提升了模型的适应度。
首先,给定N个具有区分度的样本
其中:
根据式(17)和式(18),
其中,
矩阵
(1)每行只有一维为1,其余维为0;
(2)每列最多有一维为1,其余维为0;
(3)
向量
(1)当特征维度减少时,
(2)当特征维度增加时,如果
在新样本数据的特征维度发生变化时,无法根据式(15)来计算
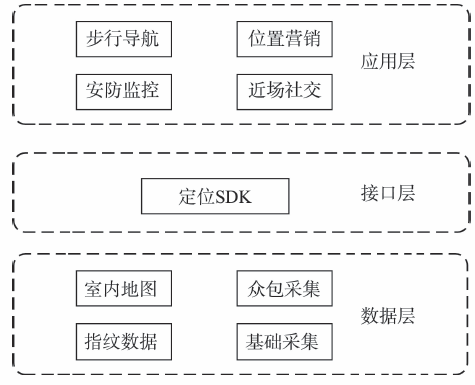
基于本文提出的室内定位方法,解决了基于位置指纹模型的室内定位方法在更新定位模型时遇到的3个难点问题,并实现了基于众包数据的室内定位平台,系统整体架构如图3所示。
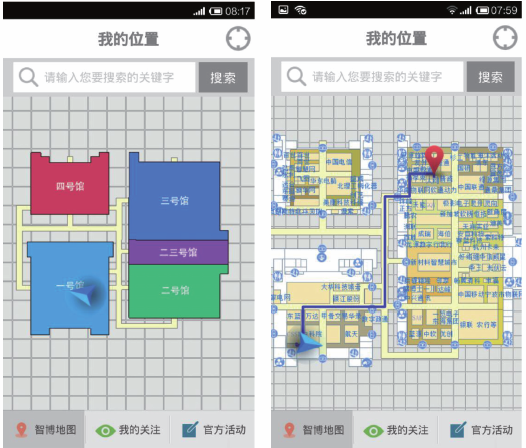
4.1.1 室内地图
在基础数据采集阶段和实际定位阶段,都需要用到室内地图。借助绘制准确的室内地图,基础采集阶段能对采集区域进行准确的位置映射标定,实际定位阶段能将定位结果直观、实时地呈现给用户。
4.1.2 指纹数据
指纹数据用于训练指纹定位模型,通过基础采集和众包采集2种数据采集方式,能得到大量训练样本,从而进行模型训练和更新。
(1)基础采集
对于位置指纹算法,初始指纹模型必须通过监督学习的方式得到,即初始训练时应采用有标定样本数据,而基础采集则用于得到相应的标定训练样本。在本定位平台中,基础采集部分由专门的数据采集客户端实现,对于从未采集过位置指纹数据的室内环境,通过制作相应的环境地图并结合数据采集客户端采集足够多的标定样本数据,训练出一个初始的位置指纹模型并应用于定位计算。
(2)众包采集
基础采集只用做训练初始定位模型,而在后续模型更新过程中,如果每次都通过人工的方式大批量采集标定样本数据,其工作量巨大,而众包采集则较好地解决了该问题。客户端在实时定位的过程中会自动进行无标定指纹数据采集,同时每一次位置估计都采集了相应的无标定样本,而用户使用定位平台的次数越多,时间越长,采集到的无标定样本数据也就越丰富。通过众包采集的方式能够得到海量的非标定样本,充分利用这些无标定样本来实时增量更新定位模型,一方面减少了人工采集标定数据的工作量,另一方面也能使指纹模型的定位精度长时间内维持在较高水平。
接口层提供定位引擎调用SDK,该SDK实现了定位核心算法,并封装为应用接口以供第三方应用程序调用。SDK的整体架构包含接口模块、数据加载模块和定位计算模块3个模块(图4)。
(1)接口模块
接口模块是对SDK整体框架的抽象封装,通过暴露简单的调用接口并结合回调机制来实现SDK底层和应用之间的数据通信和交互,第三方应用无需了解SDK的内部实现原理,便可轻松在应用中集成室内定位功能。
(2)数据加载模块
在执行定位计算前,SDK需将指纹数据加载至系统内存,然后才能进行位置计算。由于无法一次性将所有指纹数据加载到内存,在定位SDK中实现了基于新鲜度的缓存更新机制。通过该机制,SDK能减少从外部存储读取指纹的次数,有效地规避了IO瓶颈,提升了SDK的性能。
(3)定位计算模块
SDK加载完指纹数据后先进行AP扫描来采集定位数据,然后调用核心定位算法进行位置计算,最后将定位结果以接口回调的方式返回给应用,最终应用将定位结果以地图坐标的形式呈献给用户,同时SDK根据当前定位结果调用缓存更新算法进行异步指纹更新,保证当前缓存中指纹数据的有 效性。
在定位SDK提供的定位和导航服务的基础上,根据实际的应用场景以及用户需求,能够实现不同的应用。如在陌生环境中,通过定位平台提供的实时导航功能,用户能快速到达目的地;商超可通过定位平台对目标用户推送促销活动信息,进行精准位置营销;通过在小区、智慧楼宇搭建定位平台,能极大提高社区的安全;基于位置的定位服务结合儿童手表打造智能防丢器,有效地保障了儿童在户外的安全性等。由此可见,基于众包数据的定位平台在步行导航、位置营销、安防监控和近场社交等领域均有丰富的应用场景。
大型商场的商家为了吸引消费者,会不定期推出各种优惠活动进行促销,但是在购物O-2-O闭环系统形成前,商家无法有效地把自身的促销信息及时推送给消费者。对消费者而言,他们在购物时无法有效地获知他们所在位置的周围商铺提供商品信息,无法获知是否有商家正在进行商品促销。对商场而言,他们希望对进入商场的消费者进行消费行为分析,以便于他们对商场进行改进,吸引更多商家入驻,吸引更多消费者进行消费。通过将自身的定位平台与大型商场、超市进行结合,实现了完整的购物导航系统(图5),实现了O-2-O闭环的关键一步。用户只需要安装集成了定位导航功能的商场APP,进入商场后能实时收到周围商铺的推送信息,即使陌生的环境,他们也能通过APP的导航和路径规划顺利到达目的商铺。另外,用户可以在任何时间地点打开对应商场的APP,挑选喜爱的商品,然后直接到商场购买;同时,APP能记录消费者的常去的店铺,记录消费习惯,在积累一定数据后,商场便能从数据中挖掘潜在的商业价值。
与商场、超市的导航需求不同,博览会导航是一种偶发性、短时性的应用场景。随着智慧城市的不断推进,相关技术与应用如雨后春笋层出不穷,博览会作为科技产业化的展示平台,承担着技术普及和推广的重大责任,如何及时有效地向客户推荐展品信息成为博览会的首要需求。当身处产品博览会时,由于对环境缺乏了解,面对着宽阔的展厅和数量繁多的展品,迫切希望短时间内获取丰富信息的客户往往会无所适从。利用定位平台的技术特点结合博览会需求,打造了面向展会的导航应用,如图6所示。该应用能提供展会的整体位置示意图,详细标识所有参展产品的位置,当用户对某一产品感兴趣时,只需通过简单操作,应用便能规划出当前位置到目标点的路径,指引用户到达。同时在用户走近某一展品区域时,应用能自动推送该产品的相关信息,既方便又快捷,真正实现了智慧博览。
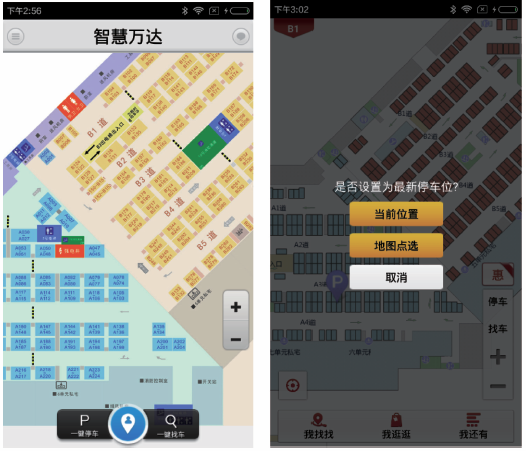
另一个基于位置服务的典型需求是停车导航。大型停车场找车一直是一个难题,多个大型商场的地下停车场动辄上千个车位,如果用户不熟悉停车场的布局而停车场又缺乏简单明了的指示牌时,车主在找车上往往要花上很长时间。为了帮车主解决该难题,推出了停车场智能停车,如图7所示。车主只需要在停车时打开定位APP,记录当前位置,然后在用户想取车时,在任意位置再次打开APP,选择找车,APP便能根据当前位置和汽车所在位置自动规划路径,引导车主快速找到自己的汽车,为车主节省了大量找车时间。
针对基于指纹模型的Wi-Fi室内定位方法存在的3个核心问题:数据增量问题、增量数据的时效问题和数据特征维度不等长问题,本文分别引入了SELM.TMELM.FA-OSELM方法,从3个层面进行解决,有效提升了定位精度和稳定性,同时实现了基于众包数据的室内定位平台,将Wi-Fi定位与实际应用相结合,取得良好效果。下一步的工作将侧重Wi-Fi定位的更多具体应用,增强定位平台的稳定性,提升用户体验。
The authors have declared that no competing interests exist.
| [1] |
Chundi X I U. Indoor positioning based on wi-fi fingerprint technique using fuzzy k-nearest neighbor [ |
| [2] |
The Horus WLAN location determination system [ |
| [3] |
et al. Indoor location recognition using fusion of SVM-based visual classifiers [ |
| [4] |
et al. Fila: Fine-grained indoor localization [ |
| [5] |
et al. You are facing the Mona Lisa: spot localization using PHY layer information [ |
| [6] |
Principal component localization in indoor WLAN environments [J].https://doi.org/10.1109/TMC.2011.30 URL [本文引用: 1] 摘要
This paper presents a novel approach to building a WLAN-based location fingerprinting system. Our algorithm intelligently transforms received signal strength (RSS) into principal components (PCs) such that the information of all access points (APs) is more efficiently utilized. Instead of selecting APs, the proposed technique replaces the elements with a subset of PCs to simultaneously improve the accuracy and reduce the online computation. Our experiments are conducted in a realistic WLAN environment. The results show that the mean error is reduced by 33.75 percent, and the complexity by 40 percent, as compared to the existing methods. Moreover, several benefits of our algorithm are demonstrated, such as requiring fewer training samples and enhancing the robustness to RSS anomalies.
|
| [7] |
et al. Transferring Localization Models over Time [ |
| [8] |
et al. Adaptive localization through transfer learning in indoor wi-fi environment [ |
| [9] |
et al. SELM: semi-supervisedELM with application in sparse calibrated location estimation [J].https://doi.org/10.1016/j.neucom.2010.12.043 URL [本文引用: 2] 摘要
Indoor location estimation based on Wi-Fi has attracted more and more attention from both research and industry fields. It brings two significant challenges. One is requiring a vast amount of labeled calibration data. The other is real-time training and testing for location estimation task. Traditional machine learning methods cannot get high performance in both aspects. This paper proposed a novel semi-supervised learning method SELM (semi-supervised extreme learning machine) and applied it to sparse calibrated location estimation. There are two advantages of the proposed SELM. First, it employs graph Laplacian regularization to import large number of unlabeled samples which can dramatically reduce labeled calibration samples. Second, it inherits the good property of ELM on extreme training and testing speed. Comparative experiments show that with same number of labeled samples, our method outperforms original ELM and back propagation (BP) network, especially in the case that the calibration data is very sparse.
|
| [10] |
具有时效机制的增量式无线定位方法 [J].https://doi.org/10.3724/SP.J.1016.2013.01448 URL [本文引用: 2] 摘要
基于WLAN(Wireless Local Area Networks)的无线定位是移动互联网领域的重要研究内容之一.其中,指纹定位方法已成为主流,此类方法的特点之一在于需要离线训练数据与在线测试数据具有严格的一致性.但在实际环境中,无线信号数据波动较大,存在显著的时效性问题.这导致一定时间后,定位模型的预测精度不断下降.文中提出一种具有时效机制的增量式定位方法(Timeliness Managing Extreme Learning Machine,TMELM),一方面满足实际系统的应用需求,可随时加入新的训练数据进行在线增量式学习,另一方面融入时效机制,以最大化新增训练数据对定位模型的贡献,保持定位模型的精度.实验表明,在实际WLAN定位数据集上,文中方法相比于传统的几种增量式学习方法,具有明显的时效优势,能获得更好的定位精度.
et al. Incremental Localization in WLAN Environment with Timeliness Management [J].https://doi.org/10.3724/SP.J.1016.2013.01448 URL [本文引用: 2] 摘要
基于WLAN(Wireless Local Area Networks)的无线定位是移动互联网领域的重要研究内容之一.其中,指纹定位方法已成为主流,此类方法的特点之一在于需要离线训练数据与在线测试数据具有严格的一致性.但在实际环境中,无线信号数据波动较大,存在显著的时效性问题.这导致一定时间后,定位模型的预测精度不断下降.文中提出一种具有时效机制的增量式定位方法(Timeliness Managing Extreme Learning Machine,TMELM),一方面满足实际系统的应用需求,可随时加入新的训练数据进行在线增量式学习,另一方面融入时效机制,以最大化新增训练数据对定位模型的贡献,保持定位模型的精度.实验表明,在实际WLAN定位数据集上,文中方法相比于传统的几种增量式学习方法,具有明显的时效优势,能获得更好的定位精度.
|
| [11] |
et al. Feature adaptive online sequential extreme learning machine for lifelong indoor localization [J]. |
| [12] |
Extreme learning machine: a new learning scheme of feedforward neural networks [ |
| [13] |
Extreme learning machine: theory and applications [J].https://doi.org/10.1016/j.neucom.2005.12.126 URL 摘要
It is clear that the learning speed of feedforward neural networks is in general far slower than required and it has been a major bottleneck in their applications for past decades. Two key reasons behind may be: (1) the slow gradient-based learning algorithms are extensively used to train neural networks, and (2) all the parameters of the networks are tuned iteratively by using such learning algorithms. Unlike these conventional implementations, this paper proposes a new learning algorithm called e xtreme l earning m achine (ELM) for s ingle-hidden l ayer f eedforward neural n etworks (SLFNs) which randomly chooses hidden nodes and analytically determines the output weights of SLFNs. In theory, this algorithm tends to provide good generalization performance at extremely fast learning speed. The experimental results based on a few artificial and real benchmark function approximation and classification problems including very large complex applications show that the new algorithm can produce good generalization performance in most cases and can learn thousands of times faster than conventional popular learning algorithms for feedforward neural networks. 1
|
| [14] |
Universal approximation using incremental constructive feedforward networks with random hidden nodes [J].https://doi.org/10.1109/TNN.2006.875977 URL PMID: 16856652 [本文引用: 1] 摘要
According to conventional neural network theories, single-hidden-layer feedforward networks (SLFNs) with additive or radial basis function (RBF) hidden nodes are universal approximators when all the parameters of the networks are allowed adjustable. However, as observed in most neural network implementations, tuning all the parameters of the networks may cause learning complicated and inefficient, and it may be difficult to train networks with nondifferential activation functions such as threshold networks. Unlike conventional neural network theories, this paper proves in an incremental constructive method that in order to let SLFNs work as universal approximators, one may simply randomly choose hidden nodes and then only need to adjust the output weights linking the hidden layer and the output layer. In such SLFNs implementations, the activation functions for additive nodes can be any bounded nonconstant piecewise continuous functions g : R --> R and the activation functions for RBF nodes can be any integrable piecewise continuous functions g : R --> R and integral of R g(x)dx not equal to 0. The proposed incremental method is efficient not only for SFLNs with continuous (including nondifferentiable) activation functions but also for SLFNs with piecewise continuous (such as threshold) activation functions. Compared to other popular methods such a new network is fully automatic and users need not intervene the learning process by manually tuning control parameters.
|
| [15] |
Generalized inverse of matrices and its applications [M]. |
| [16] |
Matrices: Theory and Applications [M]. |
| [17] |
Spectral graph theory [ |
| [18] |
Regularization and semi-supervised learning on large graphs [
|
| [19] |
Manifold regularization: A geometric framework for learning from labeled and unlabeled examples [J].https://doi.org/10.1007/s10846-006-9077-x URL 摘要
We propose a family of learning algorithms based on a new form of regularization that allows us to exploit the geometry of the marginal distribution. We focus on a semi-supervised framework that incorporates labeled and unlabeled data in a general-purpose learner. Some transductive graph learning algorithms and standard methods including support vector machines and regularized least squares can be obtained as special cases. We use properties of reproducing kernel Hilbert spaces to prove new Representer theorems that provide theoretical basis for the algorithms. As a result (in contrast to purely graph-based approaches) we obtain a natural out-of-sample extension to novel examples and so are able to handle both transductive and truly semi-supervised settings. We present experimental evidence suggesting that our semi-supervised algorithms are able to use unlabeled data effectively. Finally we have a brief discussion of unsupervised and fully supervised learning within our general framework.
|
| [20] |
et al. Fast Incremental Method for nonconvex optimization [J].
We analyze a fast incremental aggregated gradient method for optimizing nonconvex problems of the form $\min_x \sum_i f_i(x)$. Specifically, we analyze the SAGA algorithm within an Incremental First-order Oracle framework, and show that it converges to a stationary point provably faster than both gradient descent and stochastic gradient descent. We also discuss a Polyak's special class of nonconvex problems for which SAGA converges at a linear rate to the global optimum. Finally, we analyze the practically valuable regularized and minibatch variants of SAGA. To our knowledge, this paper presents the first analysis of fast convergence for an incremental aggregated gradient method for nonconvex problems.
|
| [21] |
et al. An improved wi-fi indoor positioning algorithm by weighted fusion [J].https://doi.org/10.3390/s150921824 URL PMID: 26334278 [本文引用: 1] 摘要
The rapid development of mobile Internet has offered the opportunity for WiFi indoor positioning to come under the spotlight due to its low cost. However, nowadays the accuracy of WiFi indoor positioning cannot meet the demands of practical applications. To solve this problem, this paper proposes an improved WiFi indoor positioning algorithm by weighted fusion. The proposed algorithm is based on traditional location fingerprinting algorithms and consists of two stages: the offline acquisition and the online positioning. The offline acquisition process selects optimal parameters to complete the signal acquisition, and it forms a database of fingerprints by error classification and handling. To further improve the accuracy of positioning, the online positioning process first uses a pre-match method to select the candidate fingerprints to shorten the positioning time. After that, it uses the improved Euclidean distance and the improved joint probability to calculate two intermediate results, and further calculates the final result from these two intermediate results by weighted fusion. The improved Euclidean distance introduces the standard deviation of WiFi signal strength to smooth the WiFi signal fluctuation and the improved joint probability introduces the logarithmic calculation to reduce the difference between probability values. Comparing the proposed algorithm, the Euclidean distance based WKNN algorithm and the joint probability algorithm, the experimental results indicate that the proposed algorithm has higher positioning accuracy.
|

/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}